

Autoencoders are an essential component of deep learning, particularly in unsupervised machine learning tasks. In this article, we’ll explore how autoencoders function, their architecture, and the various types available. You’ll also discover their real-world applications, along with the advantages and trade-offs involved in using them.
Table of contents
- What is an autoencoder?
- Autoencoder architecture
- Types of autoencoders
- Application of autoencoders
- Advantages of autoencoders
- Disadvantages of autoencoders
What is an autoencoder?
Autoencoders are a type of neural network used in deep learning to learn efficient, lower-dimensional representations of input data, which are then used to reconstruct the original data. By doing so, this network learns the most essential features of the data during training without requiring explicit labels, making it part of self-supervised learning. Autoencoders are widely applied in tasks such as image denoising, anomaly detection, and data compression, where their ability to compress and reconstruct data is valuable.
Autoencoder architecture
An autoencoder is composed of three parts: an encoder, a bottleneck (also known as the latent space or code), and a decoder. These components work together to capture the key features of the input data and use them to generate accurate reconstructions.
Autoencoders optimize their output by adjusting the weights of both the encoder and decoder, aiming to produce a compressed representation of the input that preserves critical features. This optimization minimizes reconstruction error, which represents the difference between the input and the output data.
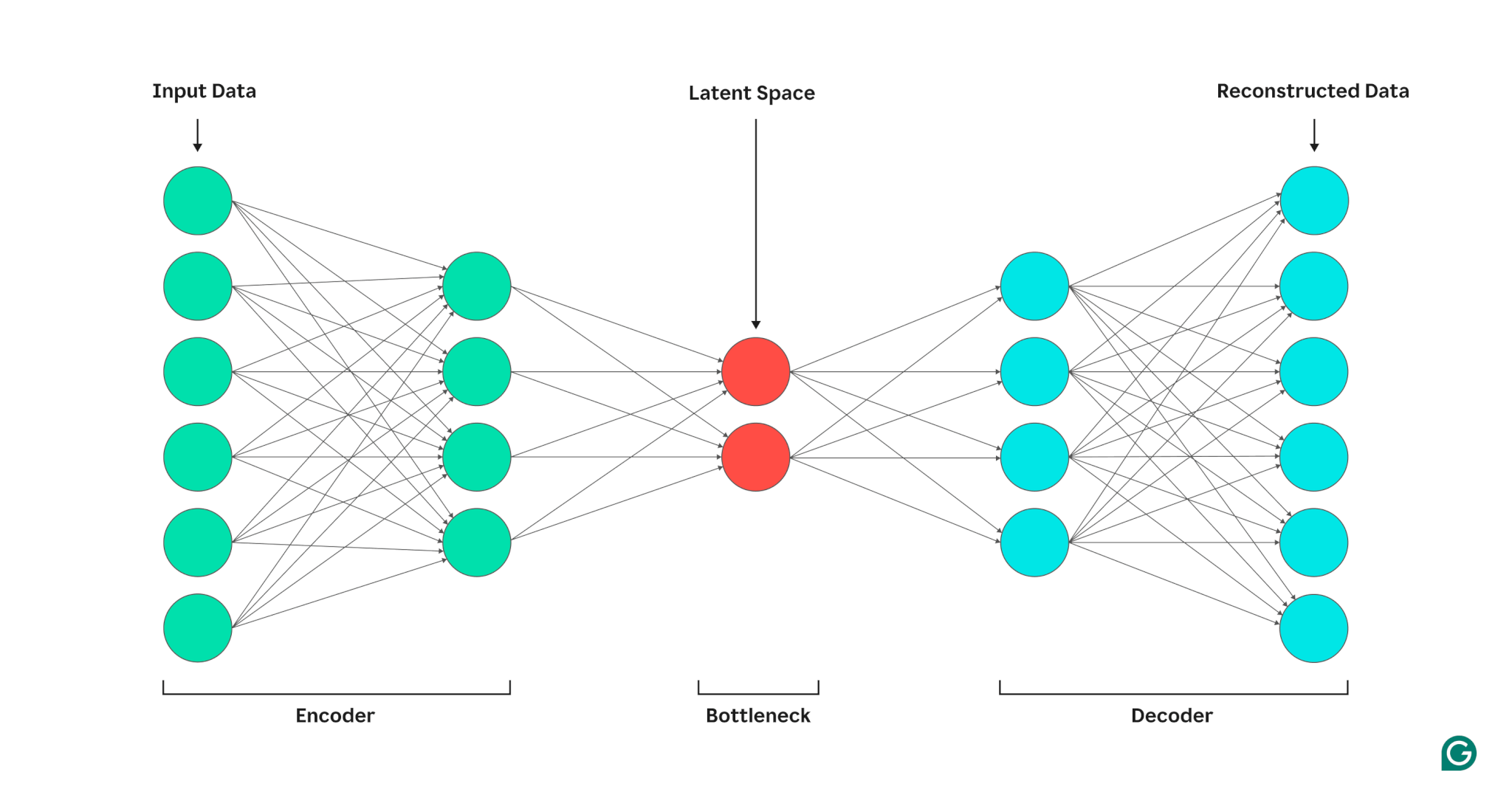
Encoder
First, the encoder compresses the input data into a more efficient representation. Encoders generally consist of multiple layers with fewer nodes in each layer. As the data is processed through each layer, the reduced number of nodes forces the network to learn the most important features of the data to create a representation that can be stored in each layer. This process, known as dimensionality reduction, transforms the input into a compact summary of the key characteristics of the data. Key hyperparameters in the encoder include the number of layers and neurons per layer, which determine the depth and granularity of the compression, and the activation function, which dictates how data features are represented and transformed at each layer.
Bottleneck
The bottleneck, also known as the latent space or code, is where the compressed representation of the input data is stored during processing. The bottleneck has a small number of nodes; this limits the amount of data that can be stored and determines the level of compression. The number of nodes in the bottleneck is a tunable hyperparameter, allowing users to control the trade-off between compression and data retention. If the bottleneck is too small, the autoencoder may reconstruct the data incorrectly due to the loss of important details. On the other hand, if the bottleneck is too large, the autoencoder may simply copy the input data instead of learning a meaningful, general representation.
Decoder
In this final step, the decoder re-creates the original data from the compressed form using the key features learned during the encoding process. The quality of this decompression is quantified using the reconstruction error, which is essentially a measure of how different the reconstructed data is from the input. Reconstruction error is generally calculated using mean squared error (MSE). Because MSE measures the squared difference between the original and reconstructed data, it provides a mathematically straightforward way to penalize larger reconstruction errors more heavily.
Types of autoencoders
There are several types of specialized autoencoders, each optimized for specific applications, similar to other neural networks.
Denoising autoencoders
Denoising autoencoders are designed to reconstruct clean data from noisy or corrupted input. During training, noise is intentionally added to input data, enabling the model to learn features that remain consistent despite the noise. Outputs are then compared to the original clean inputs. This process makes denoising autoencoders highly effective in image- and audio-noise reduction tasks, including removing background noise in video conferences.
Sparse autoencoders
Sparse autoencoders restrict the number of active neurons at any given time, encouraging the network to learn more efficient data representations compared to standard autoencoders. This sparsity constraint is enforced through a penalty that discourages activating more neurons than a specified threshold. Sparse autoencoders simplify high-dimensional data while preserving essential features, making them valuable for tasks such as extraction of interpretable features and visualization of complex datasets.
Variational autoencoders (VAEs)
Unlike typical autoencoders, VAEs generate new data by encoding features from training data into a probability distribution, rather than a fixed point. By sampling from this distribution, VAEs can generate diverse new data, instead of reconstructing the original data from the input. This capability makes VAEs useful for generative tasks, including synthetic data generation. For example, in image generation, a VAE trained on a dataset of handwritten numbers can create new, realistic-looking digits based on the training set that are not exact replicas.
Contractive autoencoders
Contractive autoencoders introduce an additional penalty term during the calculation of reconstruction error, encouraging the model to learn feature representations that are robust to noise. This penalty helps prevent overfitting by promoting feature learning that is invariant to small variations in input data. As a result, contractive autoencoders are more robust to noise than standard autoencoders.
Convolutional autoencoders (CAEs)
CAEs utilize convolutional layers to capture spatial hierarchies and patterns within high-dimensional data. The use of convolutional layers makes CAEs particularly well suited for processing image data. CAEs are commonly used in tasks like image compression and anomaly detection in images.
Applications of autoencoders in AI
Autoencoders have several applications, such as dimensionality reduction, image denoising, and anomaly detection.
Dimensionality reduction
Autoencoders are effective tools for reducing the dimensionality of input data while preserving key features. This process is valuable for tasks like visualizing high-dimensional datasets and compressing data. By simplifying the data, dimensionality reduction also enhances computational efficiency, lowering both size and complexity.
Anomaly detection
By learning the key features of a target dataset, autoencoders can distinguish between normal and anomalous data when provided with new input. Deviation from normal is indicated by higher than normal reconstruction error rates. As such, autoencoders can be applied to diverse domains like predictive maintenance and computer network security.
Denoising
Denoising autoencoders can clean noisy data by learning to reconstruct it from noisy training inputs. This capability makes denoising autoencoders valuable for tasks like image optimization, including enhancing the quality of blurry photographs. Denoising autoencoders are also useful in signal processing, where they can clean noisy signals for more efficient processing and analysis.
Advantages of autoencoders
Autoencoders have a number of key advantages. These include the ability to learn from unlabeled data, automatically learn features without explicit instruction, and extract nonlinear features.
Able to learn from unlabeled data
Autoencoders are an unsupervised machine learning model, which means that they can learn underlying data features from unlabeled data. This capability means that autoencoders can be applied to tasks where labeled data may be scarce or unavailable.
Automatic feature learning
Standard feature extraction techniques, such as principal component analysis (PCA), are often impractical when it comes to handling complex and/or large datasets. Because autoencoders were designed with tasks like dimensionality reduction in mind, they can automatically learn key features and patterns in data without manual feature design.
Nonlinear feature extraction
Autoencoders can handle nonlinear relationships in input data, allowing the model to capture key features from more complex data representations. This ability means that autoencoders have an advantage over models that can work only with linear data, as they can handle more complex datasets.
Limitations of autoencoders
Like other ML models, autoencoders come with their own set of disadvantages. These include lack of interpretability, the need for a large training datasets to perform well, and limited generalization capabilities.
Lack of interpretability
Similar to other complex ML models, autoencoders suffer from lack of interpretability, meaning that it is hard to understand the relationship between input data and model output. In autoencoders, this lack of interpretability occurs because autoencoders automatically learn features as opposed to traditional models, where features are explicitly defined. This machine-generated feature representation is often highly abstract and tends to lack human-interpretable features, making it difficult to understand what each component in the representation means.
Require large training datasets
Autoencoders typically require large training datasets to learn generalizable representations of key data features. Given small training datasets, autoencoders may tend to overfit, leading to poor generalization when presented with new data. Large datasets, on the other hand, provide the necessary diversity for the autoencoder to learn data features that can be applied across a wide range of scenarios.
Limited generalization over new data
Autoencoders trained on one dataset often have limited generalization capabilities, meaning that they fail to adapt to new datasets. This limitation occurs because autoencoders are geared toward data reconstruction based on prominent features from a given dataset. As such, autoencoders generally throw out smaller details from the data during training and cannot handle data that doesn’t fit with the generalized feature representation.





