

Overfitting is a common problem that comes up when training machine learning (ML) models. It can negatively impact a model’s ability to generalize beyond the training data, leading to inaccurate predictions in real-world scenarios. In this article, we’ll explore what overfitting is, how it occurs, the common causes behind it, and effective ways to detect and prevent it.
Table of contents
- What is overfitting?
- How overfitting occurs
- Overfitting vs. underfitting
- What causes overfitting?
- How to detect overfitting
- How to avoid overfitting
- Examples of overfitting
What is overfitting?
Overfitting is when a machine learning model learns the underlying patterns and the noise in the training data, becoming overly specialized in that specific dataset. This excessive focus on the details of the training data results in poor performance when the model is applied to new, unseen data, as it fails to generalize beyond the data it was trained on.
How does overfitting happen?
Overfitting occurs when a model learns too much from the specific details and noise in the training data, making it overly sensitive to patterns that are not meaningful to generalization. For example, consider a model built to predict employee performance based on historical evaluations. If the model overfits, it might focus too much on specific, non-generalizable details, such as the unique rating style of a former manager or particular circumstances during a past review cycle. Rather than learning the broader, meaningful factors that contribute to performance—like skills, experience, or project outcomes—the model may struggle to apply its knowledge to new employees or evolve evaluation criteria. This leads to less accurate predictions when the model is applied to data that differs from the training set.
Overfitting vs. underfitting
In contrast to overfitting, underfitting occurs when a model is too simple to capture the underlying patterns in the data. As a result, it performs poorly on the training as well as on new data, failing to make accurate predictions.
To visualize the difference between underfitting and overfitting, imagine we’re trying to predict athletic performance based on a person’s stress level. We can plot the data and show three models that attempt to predict this relationship:

1 Underfitting: In the first example, the model uses a straight line to make predictions, while the actual data follows a curve. The model is too simple and fails to capture the complexity of the relationship between stress level and athletic performance. As a result, the predictions are mostly inaccurate, even for the training data. This is underfitting.
2 Optimal fit: The second example shows a model that strikes the right balance. It captures the underlying trend in the data without overcomplicating it. This model generalizes well to new data because it doesn’t attempt to fit every small variation in the training data—just the core pattern.
3 Overfitting: In the final example, the model uses a highly complex, wavy curve to fit the training data. While this curve is very accurate for the training data, it also captures random noise and outliers that don’t represent the actual relationship. This model is overfitting because it’s so finely tuned to the training data that it’s likely to make poor predictions on new, unseen data.
Common causes of overfitting
Now we know what overfitting is and why it happens, let’s explore some common causes in more detail:
- Insufficient training data
- Inaccurate, erroneous, or irrelevant data
- Large weights
- Overtraining
- Model architecture is too sophisticated
Insufficient training data
If your training dataset is too small, it may represent only some of the scenarios the model will encounter in the real world. During training, the model may fit the data well. However, you might see significant inaccuracies once you test it on other data. The small dataset limits the model’s ability to generalize to unseen situations, making it prone to overfitting.
Inaccurate, erroneous, or irrelevant data
Even if your training dataset is large, it may contain errors. These errors could arise from various sources, such as participants providing false information in surveys or faulty sensor readings. If the model attempts to learn from these inaccuracies, it will adapt to patterns that don’t reflect the true underlying relationships, leading to overfitting.
Large weights
In machine learning models, weights are numerical values that represent the importance assigned to specific features in the data when making predictions. When weights become disproportionately large, the model may overfit, becoming overly sensitive to certain features, including noise in the data. This happens because the model becomes too reliant on particular features, which harms its ability to generalize to new data.
Overtraining
During training, the algorithm processes data in batches, calculates the error for each batch, and adjusts the model’s weights to improve its accuracy.
Is it a good idea to continue training for as long as possible? Not really! Prolonged training on the same data can cause the model to memorize specific data points, limiting its ability to generalize to new or unseen data, which is the essence of overfitting. This type of overfitting can be mitigated by using early stopping techniques or monitoring the model’s performance on a validation set during training. We’ll discuss how this works later in the article.
Model architecture is too complex
A machine learning model’s architecture refers to how its layers and neurons are structured and how they interact to process information.
More complex architectures can capture detailed patterns in the training data. However, this complexity increases the likelihood of overfitting, as the model may also learn to capture noise or irrelevant details that do not contribute to accurate predictions on new data. Simplifying the architecture or using regularization techniques can help reduce the risk of overfitting.
How to detect overfitting
Detecting overfitting can be tricky because everything may appear to be going well during training, even when overfitting is happening. The loss (or error) rate—a measure of how often the model is wrong—will continue to decrease, even in an overfitting scenario. So, how can we know if overfitting has occurred? We need a reliable test.
One effective method is using a learning curve, a chart that tracks a measure called loss. The loss represents the magnitude of the error the model is making. However, we don’t just track the loss for the training data; we also measure the loss on unseen data, called validation data. This is why the learning curve typically has two lines: training loss and validation loss.
If the training loss continues to decrease as expected, but the validation loss increases, this suggests overfitting. In other words, the model is becoming overly specialized to the training data and struggling to generalize to new, unseen data. The learning curve might look something like this:
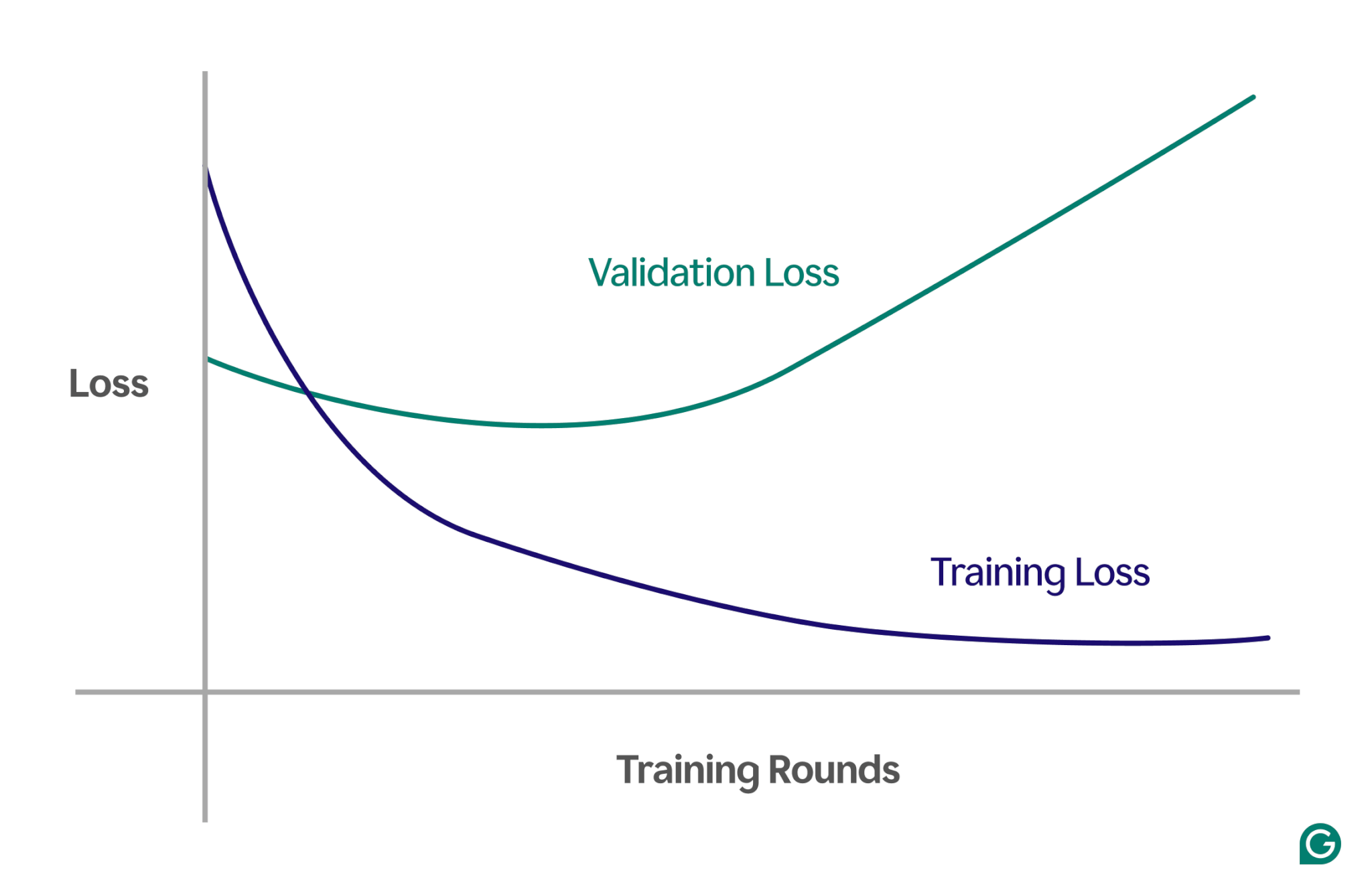
In this scenario, while the model improves during training, it performs poorly on unseen data. This likely means that overfitting has occurred.
How to avoid overfitting
Overfitting can be addressed using several techniques. Here are some of the most common methods:
Reduce the model size
Most model architectures allow you to adjust the number of weights by changing the number of layers, layer sizes, and other parameters known as hyperparameters. If the complexity of the model is causing overfitting, reducing its size can help. Simplifying the model by reducing the number of layers or neurons can lower the risk of overfitting, as the model will have fewer opportunities to memorize the training data.
Regularize the model
Regularization involves modifying the model to discourage large weights. One approach is to adjust the loss function so that it measures error and includes the size of the weights.
With regularization, the training algorithm minimizes both the error and the size of the weights, reducing the likelihood of large weights unless they provide a clear advantage to the model. This helps prevent overfitting by keeping the model more generalized.
Add more training data
Increasing the size of the training dataset can also help prevent overfitting. With more data, the model is less likely to be influenced by noise or inaccuracies in the dataset. Exposing the model to more varied examples will make it less inclined to memorize individual data points and instead learn broader patterns.
Apply dimensionality reduction
Sometimes, the data may contain correlated features (or dimensions), meaning several features are related in some way. Machine learning models treat dimensions as independent, so if features are correlated, the model might focus too heavily on them, leading to overfitting.
Dimensionality reduction techniques, such as principal component analysis (PCA), can reduce these correlations. PCA simplifies the data by reducing the number of dimensions and removing correlations, making overfitting less likely. By focusing on the most relevant features, the model becomes better at generalizing to new data.
Practical examples of overfitting
To better understand overfitting, let’s explore some practical examples across different fields where overfitting can lead to misleading results.
Image classification
Image classifiers are designed to recognize objects in images—for example, whether a picture contains a bird or a dog.
Other details may correlate with what you’re trying to detect in these pictures. For instance, dog photos might frequently have grass in the background, while bird photos might often have a sky or treetops in the background.
If all the training images have these consistent background details, the machine learning model may start relying on the background to recognize the animal, rather than focusing on the actual features of the animal itself. As a result, when the model is asked to classify an image of a bird perched on a lawn, it may incorrectly classify it as a dog because it’s overfitting to the background information. This is a case of overfitting to the training data.
Financial modeling
Let’s say you’re trading stocks in your spare time, and you believe it’s possible to predict price movements based on the trends of Google searches for certain keywords. You set up a machine learning model using Google Trends data for thousands of words.
Since there are so many words, some will likely show a correlation with your stock prices purely by chance. The model may overfit these coincidental correlations, making poor predictions on future data because the words aren’t relevant predictors of stock prices.
When building models for financial applications, it’s important to understand the theoretical basis for the relationships in the data. Feeding large datasets into a model without careful feature selection can increase the risk of overfitting, especially when the model identifies spurious correlations that exist purely by chance in the training data.
Sports superstition
Although not strictly related to machine learning, sports superstitions can illustrate the concept of overfitting—particularly when results are tied to data that logically has no connection to the outcome.
During the UEFA Euro 2008 soccer championships and the 2010 FIFA World Cup, an octopus named Paul was famously used to predict match outcomes involving Germany. Paul got four out of six predictions correct in 2008 and all seven in 2010.
If you only consider the “training data” of Paul’s past predictions, a model that agrees with Paul’s choices would appear to predict outcomes very well. However, this model would not be generalized well to future games, as the octopus’s choices are unreliable predictors of match outcomes.





