

Random forests are a powerful and versatile technique in machine learning (ML). This guide will help you understand random forests, how they work and their applications, benefits, and challenges.
Table of contents
Decision trees vs. random forest: What’s the difference?
Practical applications of random forests
Disadvantages of random forests
What is a random forest?
A random forest is a machine learning algorithm that uses multiple decision trees to make predictions. It is a supervised learning method designed for both classification and regression tasks. By combining the outputs of many trees, a random forest improves accuracy, reduces overfitting, and provides more stable predictions compared to a single decision tree.
Decision trees vs. random forest: What’s the difference?
Although random forests are built on decision trees, the two algorithms differ significantly in structure and application:
Decision trees
A decision tree consists of three main components: a root node, decision nodes (internal nodes), and leaf nodes. Like a flowchart, the decision process starts at the root node, flows through the decision nodes based on conditions, and ends at a leaf node representing the outcome. While decision trees are easy to interpret and conceptualize, they’re also prone to overfitting, especially with complex or noisy datasets.
Random forests
A random forest is an ensemble of decision trees that combines their outputs for improved predictions. Each tree is trained on a unique bootstrap sample (a randomly sampled subset of the original dataset with replacement) and evaluates decision splits using a randomly selected subset of features at each node. This approach, known as feature bagging, introduces diversity among the trees. By aggregating the predictions—using majority voting for classification or averages for regression—random forests produce more accurate and stable results than any single decision tree in the ensemble.
How random forests work
Random forests operate by combining multiple decision trees to create a robust and accurate prediction model.
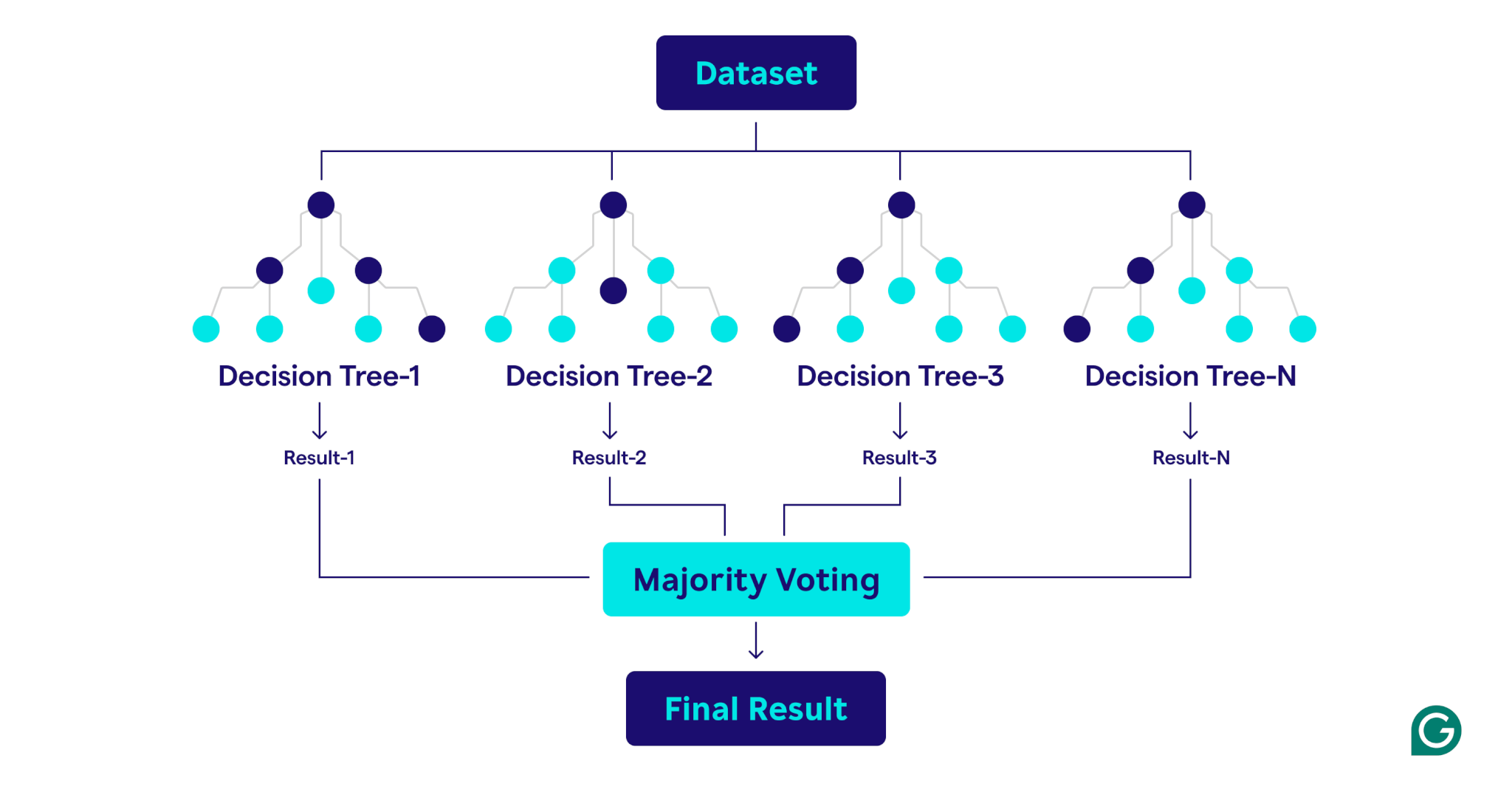
Here’s a step-by-step explanation of the process:
1. Setting hyperparameters
The first step is to define the model’s hyperparameters. These include:
- Number of trees: Determines the size of the forest
- Maximum depth for each tree: Controls how deep each decision tree can grow
- Number of features considered at each split: Limits the number of features evaluated when creating splits
These hyperparameters allow for fine-tuning the model’s complexity and optimizing performance for specific datasets.
2. Bootstrap sampling
Once the hyperparameters are set, the training process begins with bootstrap sampling. This involves:
- Data points from the original dataset are randomly selected to create training datasets (bootstrap samples) for each decision tree.
- Each bootstrap sample is typically about two-thirds the size of the original dataset, with some data points repeated and others excluded.
- The remaining third of the data points, not included in the bootstrap sample, is referred to as the out-of-bag (OOB) data.
3. Building decision trees
Each decision tree in the random forest is trained on its corresponding bootstrap sample using a unique process:
- Feature bagging: At each split, a random subset of features is selected, ensuring diversity among the trees.
- Node splitting: The best feature from the subset is used to split the node:
- For classification tasks, criteria like Gini impurity (a measure of how often a randomly chosen element would be incorrectly classified if it were randomly labeled according to the distribution of class labels in the node) measure how well the split separates the classes.
- For regression tasks, techniques like variance reduction (a method that measures how much splitting a node decreases the variance of the target values, leading to more precise predictions) evaluate how much the split reduces prediction error.
- The tree grows recursively until it meets stopping conditions, such as a maximum depth or a minimum number of data points per node.
4. Evaluating performance
As each tree is constructed, the model’s performance is estimated using the OOB data:
- The OOB error estimation provides an unbiased measure of model performance, eliminating the need for a separate validation dataset.
- By aggregating predictions from all the trees, the random forest achieves improved accuracy and reduces overfitting compared to individual decision trees.
Practical applications of random forests
Like the decision trees on which they are built, random forests can be applied to classification and regression problems in a wide variety of sectors, such as healthcare and finance.
Classifying patient conditions
In healthcare, random forests are used to classify patient conditions based on information like medical history, demographics, and test results. For example, to predict whether a patient is likely to develop a specific condition like diabetes, each decision tree classifies the patient as at risk or not based on relevant data, and the random forest makes the final determination based on a majority vote. This approach means that random forests are particularly well suited for the complex, feature-rich datasets found in healthcare.
Predicting loan defaults
Banks and major financial institutions widely use random forests to determine loan eligibility and better understand risk. The model uses factors like income and credit score to determine risk. Because risk is measured as a continuous numerical value, the random forest performs regression instead of classification. Each decision tree, trained on slightly different bootstrap samples, outputs a predicted risk score. Then, the random forest averages all of the individual predictions, resulting in a robust, holistic risk estimate.
Predicting customer loss
In marketing, random forests are often used to predict the likelihood of a customer discontinuing the use of a product or service. This involves analyzing customer behavior patterns, such as purchase frequency and interactions with customer service. By identifying these patterns, random forests can classify customers at risk of leaving. With these insights, companies can take proactive, data-driven steps to retain customers, such as offering loyalty programs or targeted promotions.
Predicting real estate prices
Random forests can be used to predict real estate prices, which is a regression task. To make the prediction, the random forest uses historical data that includes factors like geographic location, square footage, and recent sales in the area. The random forest’s averaging process results in a more reliable and stable price prediction than that of an individual decision tree, which is useful in the highly volatile real estate markets.
Advantages of random forests
Random forests offer numerous advantages, including accuracy, robustness, versatility, and the ability to estimate feature importance.
Accuracy and robustness
Random forests are more accurate and robust than individual decision trees. This is achieved by combining the outputs of multiple decision trees trained on different bootstrap samples of the original dataset. The resulting diversity means that random forests are less prone to overfitting than individual decision trees. This ensemble approach means that random forests are good at handling noisy data, even in complex datasets.
Versatility
Like the decision trees on which they are built, random forests are highly versatile. They can handle both regression and classification tasks, making them applicable to a wide range of problems. Random forests also work well with large, feature-rich datasets and can handle both numerical and categorical data.
Feature importance
Random forests have a built-in ability to estimate the importance of particular features. As part of the training process, random forests output a score that measures how much the accuracy of the model changes if a particular feature is removed. By averaging the scores for each feature, random forests can provide a quantifiable measure of feature importance. Less important features can then be removed to create more efficient trees and forests.
Disadvantages of random forests
While random forests offer many benefits, they are harder to interpret and more costly to train than a single decision tree, and they may output predictions more slowly than other models.
Complexity
While random forests and decision trees have much in common, random forests are harder to interpret and visualize. This complexity arises because random forests use hundreds or thousands of decision trees. The “black box” nature of random forests is a serious drawback when model explainability is a requirement.
Computational cost
Training hundreds or thousands of decision trees requires much more processing power and memory than training a single decision tree. When large datasets are involved, the computational cost can be even higher. This large resource requirement can result in higher monetary cost and longer training times. As a result, random forests may not be practical in scenarios like edge computing, where both computation power and memory are scarce. However, random forests can be parallelized, which can help reduce the computation cost.
Slower prediction time
The prediction process of a random forest involves traversing every tree in the forest and aggregating their outputs, which is inherently slower than using a single model. This process can result in slower prediction times than simpler models like logistic regression or neural networks, especially for large forests containing deep trees. For use cases where time is of the essence, such as high-frequency trading or autonomous vehicles, this delay can be prohibitive.





