

The Strategic Research team at Grammarly is constantly exploring how LLMs can contribute to our mission of improving lives by improving communication. Our previous work on CoEdIT showed that LLMs trained specifically for text editing can be of higher quality and more performant. We focused our experiments on English. However, most foundational models produced since our previous work (from 2024 and on) have been multilingual. They can understand instructions and have conversations in multiple languages. And this had us wondering: What would it take to support multiple languages with CoEdIT?
Overview
With mEdIT, we extend CoEdIT to support instructions in seven languages, both when the instructions match the language of the text and when they don’t. In our work on mEdIT, we use fine-tuning techniques similar to the ones we used for CoEdIT to produce multilingual writing assistants that are much better than previous ones. These assistants are effective even when the language of the instructions doesn’t match the language of the text (cross-lingual), can perform several kinds of editing tasks (multi-task), and do well even for some languages they haven’t specifically been trained for (generalizable).
Our work building CoEdIT and other analyses has shown that popular foundational LLMs produce low-quality outputs when asked to perform text edits. Previous attempts to fine-tune LLMs for editing tasks have focused on supporting either multiple editing tasks for a single language (almost always English), or a single editing task across several languages. Very few experiments have explored supporting several editing tasks simultaneously. Our work improves on the limitations of prior work by:
- Supporting multiple editing tasks
- Accepting edit instructions in multiple languages
- Taking edit instructions in languages that don’t match the edited text
Our models achieve strong performance across multiple languages and editing tasks. Through careful experimentation, we provide insights into how various choices affect model performance on these tasks, including model architecture, model scale, and training data mixtures. This post summarizes how we went about this work, published in our paper “mEdIT: Multilingual Text Editing via Instruction Tuning” at NAACL 2024.

Figure 1: mEdIT is multilingual and cross-lingual
Our data and models are publicly available on GitHub and Hugging Face. By making our data and models publicly available, we hope to help make advances in multilingual intelligent writing assistants.1
What we did
We followed a process similar to the one we used for CoEdIT. We fine-tuned several different types and sizes of LLMs, so we could test how model size and architecture choice impact performance.
We decided to cover three different editing tasks: grammatical error correction (GEC), text simplification, and paraphrasing. These tasks have relatively well-defined evaluation metrics and publicly available human-annotated training data covering a wide range of languages. Our training data for these tasks included more than two hundred thousand pairs of instructions and rewrite outputs, all curated from publicly available data sets. See Figure 2 for a comparison of available training data by language and edit task.
We chose to work with seven languages, which covered six diverse language families. Besides ensuring broad coverage in our selection, we also selected languages that had enough publicly available human-annotated texts. We built mEdIT by fine-tuning several multilingual LLMs on carefully curated corpora from these publicly available datasets (see the performance section below or our paper for full details). We chose Arabic, Chinese, English, German, Japanese, Korean, and Spanish as the languages for this work.
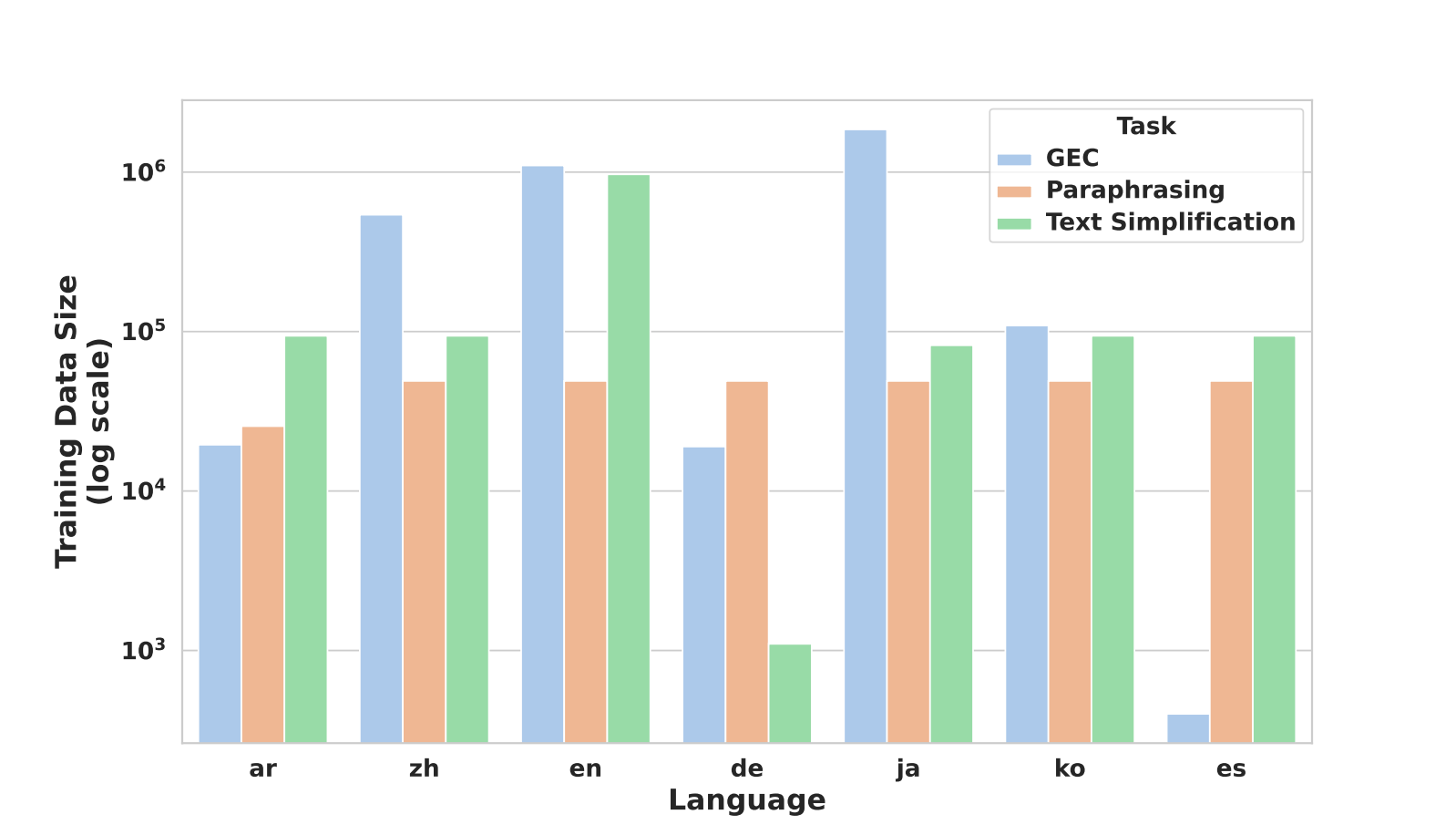
Figure 2: Relative size of available training data by language and edit task
Building the instruction-tuning dataset
To fine-tune the edit instructions, we looked at 21 combinations, supporting all three edit tasks for each of the seven languages in our training set. To make sure our instructions were accurate, we asked native language speakers to review and correct translated instructions after they were automatically generated from English versions.
We prepared the data for each edit task, including randomly sampling 10K samples from each dataset (except for Spanish GEC, where we only had 398 data points). This choice optimizes computational cost against performance, based on insights from our work on CoEdIT and follow-up experiments showing quality doesn’t improve noticeably as a function of data size; it improves as a function of data quality instead.
Training the models
We fine-tuned two types of model architectures: encoder-decoder/sequence-to-sequence (Seq2Seq) and decoder-only/causal language models (CLM) on the mEdIT dataset. The Seq2Seq models included mT5 (Xue et al., 2021) and mT0 (Raffel et al., 2020), with parameter sizes between 1.3B and 13B. For CLM we used BLOOMZ (Muennighoff et al., 2023), PolyLM (Wei et al., 2023), and Bactrian-X (Li et al., 2023) models—with model sizes ranging from 2B to 13B. All of these multilingual models were fine-tuned with our instructional data set on 8xA100 80G GPU instances.
Performance
We used existing standard evaluation metrics for the three edit tasks:
GEC: We followed prior work, using the appropriate metrics for each language—one of the MaxMatch (M2) Scorer (Dahlmeier and Ng, 2012), ERRANT (Bryant et al., 2017), and GLEU (Napoles et al., 2015, 2016). For languages evaluated with either the M2 scorer or ERRANT, we used the F0.5 measure.
Simplification: We used SARI (Xu et al., 2016a) and BLEU (Papineni et al., 2002) for evaluation, following work done by Ryan et al. (2023). SARI correlates with human judgments of simplicity, and BLEU is a common machine translation metric that we used as a proxy for evaluating fluency and meaning preservation against references.
Paraphrasing: We used Self-BLEU (Zhu et al., 2018) to evaluate diversity relative to the source text, and mUSE (Yang et al., 2020) to evaluate semantic similarity and meaning preservation. We also considered other popular metrics, such as Multilingual-SBERT (Reimers and Gurevych, 2020) and LaBSE (Feng et al., 2022), but they were unsuitable for our purposes.
Multilingually trained models outperform regardless of instruction language
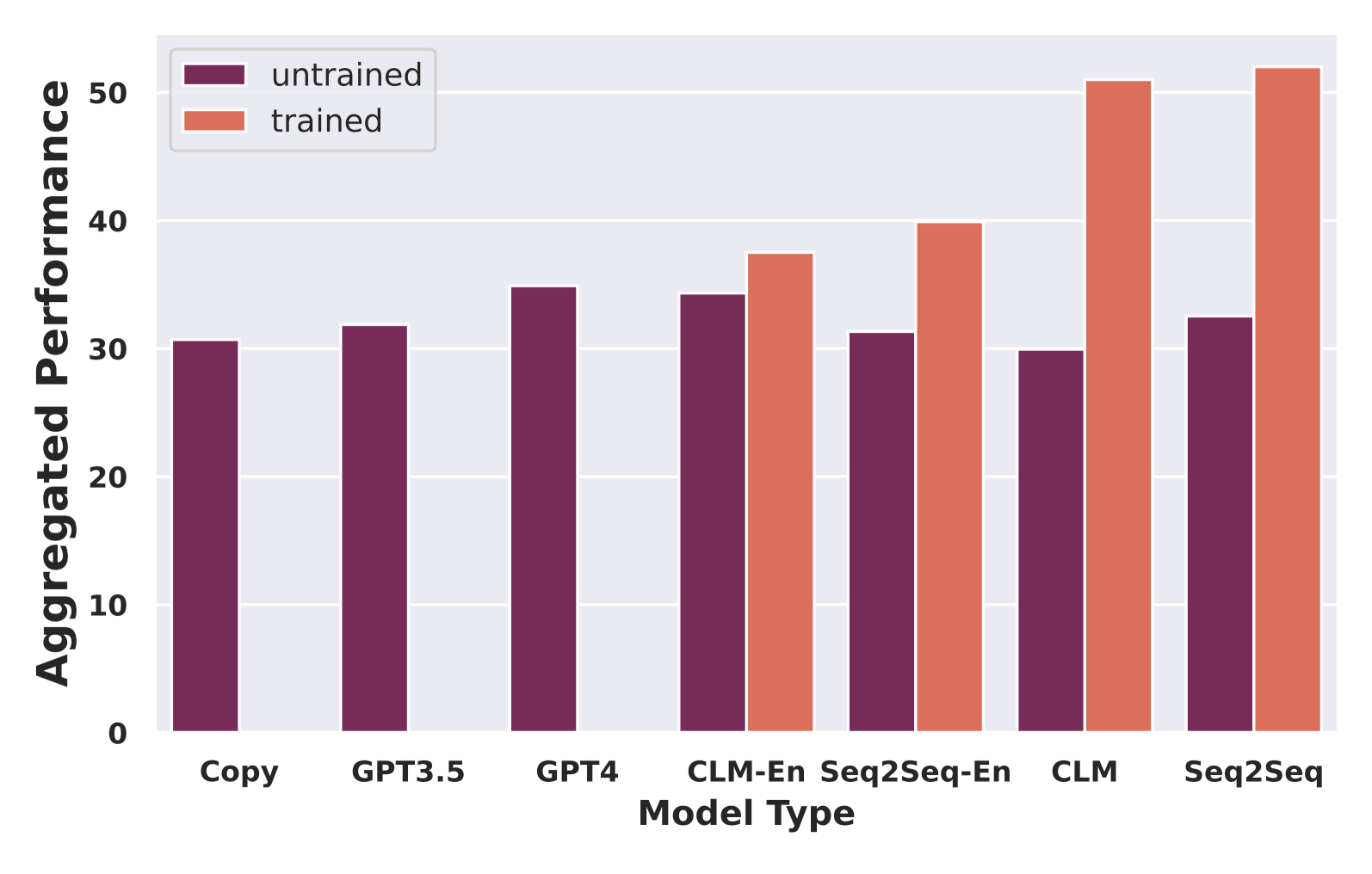
Figure 3: Performance of all baselines against trained models
To evaluate our work across instruction languages, first, we compared our work against three different zero-shot baselines (copying input to output, GPT3.5, and GPT4). We assessed two test cases—a partial training case, with our models trained just on English instructions (the -en suffix models in Figure 3 above), and a case where our models were trained on the full multilingual sets. We calculated performance across all tasks using the harmonic mean of task-specific scores. A core contribution of our work is to push the performance of small- (~1B) to medium-sized LLMs (1-15B parameters) for common editing tasks across multiple languages, and we show a substantial improvement over their untrained counterparts. In general, models trained with multilingual instructions perform much better than the rest.
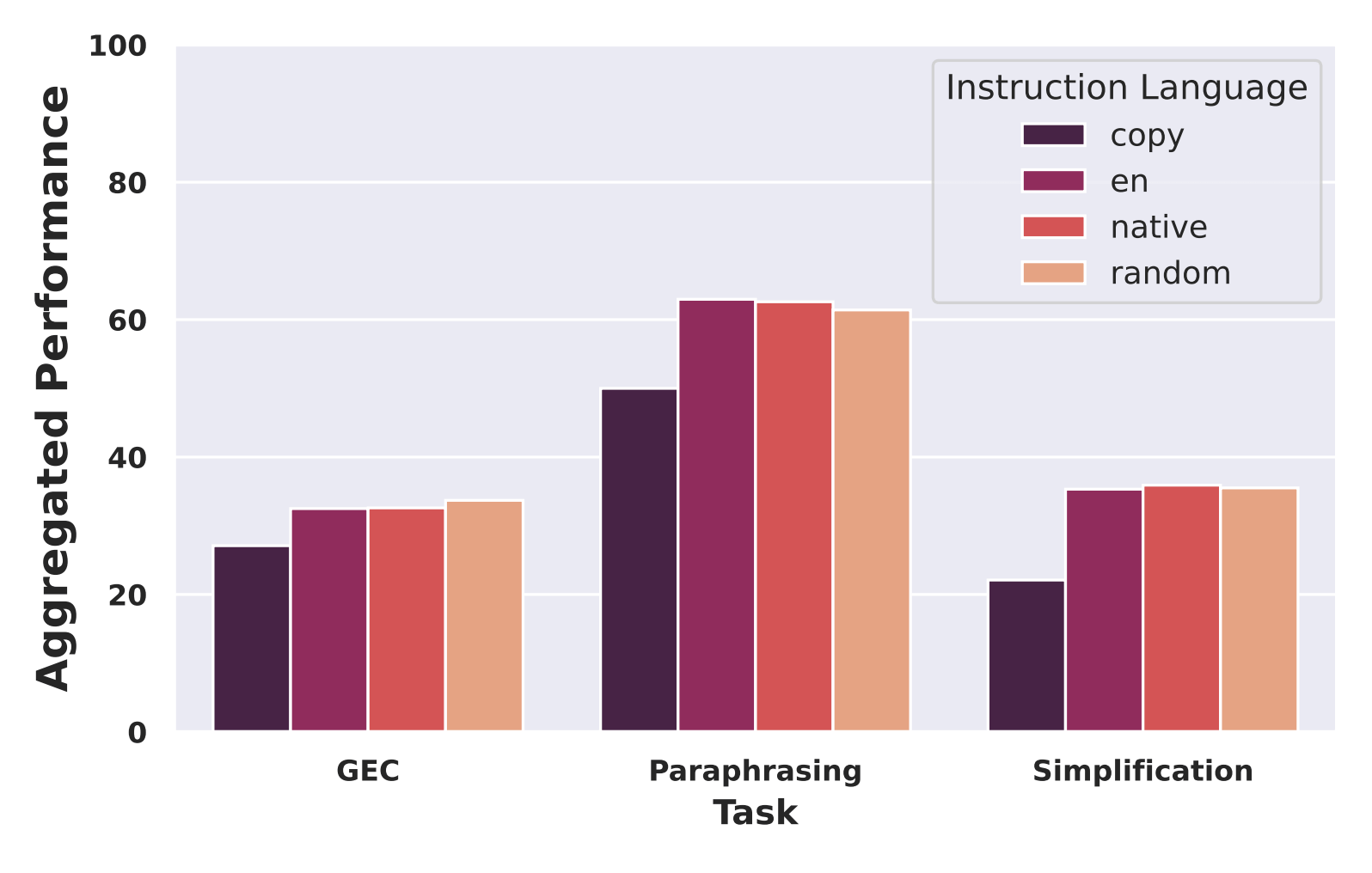
Figure 4: Aggregated performance on different tasks broken down by instruction language
To evaluate our work across the language of instruction, we ran four different sets of experiments:
- No-edits: As a baseline, we evaluated copying the source to the output and scored it.
- English: All instructions to the models were in English.
- Native: The instructions matched the language of the text being edited.
- Random: The instructions were in a random language.
In aggregate, performance was stable across our test cases (see Figure 4). Models performed at the same high level no matter what language the instructions were in or whether the language matched the body of the text. Likely this is a consequence of each model’s multilingual instructional pre-training, which should allow them to adapt well during the fine-tuning phase.
Performance on edited language is correlated with available training data
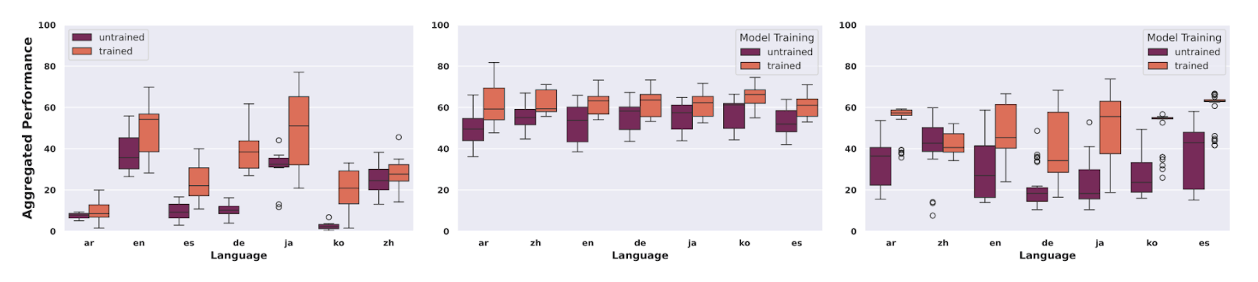
Figure 5: Aggregate model performance by language (for GEC, Paraphrasing, and Simplification, respectively)
When grouped by edit task, the variance in performance across languages is correlated with the amount and quality of data available for each. German, for example, with only 1.1K data points, showed both a very large improvement with fine tuning and a great variance in results. We partially attribute the steady performance of Paraphrasing to the weakness of the evaluation metrics (they rely mostly on n-gram overlap), to the large model size and fine-tuning (larger and more tuned models tend to make fewer changes), and to the multilingual pre-training of the LLMs where they see medium-large corpora of nearly all of the languages—see Figure 5 for details.
mEdIT generalizes to unseen languages
For each task, we tested our models on languages not seen during training—one language related to the six language families we covered in training and one that wasn’t. These were, however, languages that the underlying LLM had been pre-trained on, so the models did understand them.
When we compare the performance of mEdIT to the monolingual state of the art, it is competitive on multiple language-edit task combinations, especially Simplification for Italian, and GEC and Paraphrasing for Hindi (see the table below).
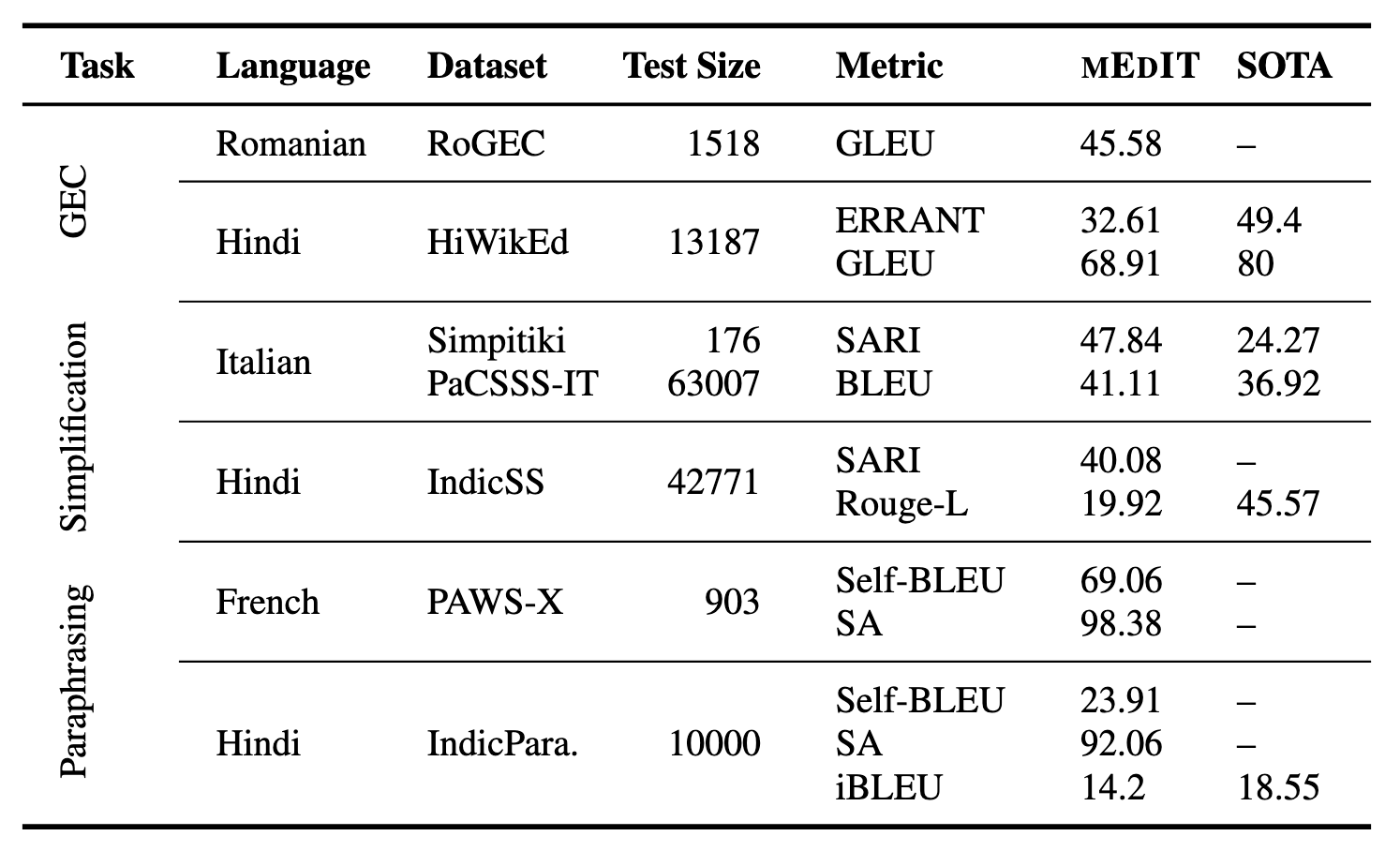
Table 1: Results from language generalization experiments
Training generalizes across edit tasks
To measure the impact of individual edit task training on overall performance, we systematically ablated portions of data for each task and observed how that impacted performance. As expected, lower amounts of training data for a task led to lower performance on that specific task. We noticed, however, that the training translates across tasks, and sometimes training for one improves performance for another. Increased training for GEC translates into improved performance on simplification and paraphrasing, for example. And the same holds for the other tasks.
CLMs performed best, and performance increased with model size
When evaluated individually, CLMs either matched or exceeded the performance of all other models. Seq2Seq models have slightly higher BLEU scores than CLMs on Simplification, which we suspect results from Seq2Seq models producing shorter sequences in general.
Surprisingly, especially considering GPT4’s multilingual capabilities, both GPT3.5 and GPT4 performed poorly relative to the other models, with GPT3.5 performing the least well of all the models we considered. This may be an artifact of our metrics since GLEU relies on overlap with reference material, and reinforced learning from human reference (RLHF) can produce excellent results that don’t overlap. Further work into developing more robust metrics might provide better insights.
As expected, model size is crucial, and larger models show significantly improved performance across all tasks, especially for GEC and Paraphrasing.
Human feedback
We collected feedback from expert annotators, using a process similar to the process we followed for the CoEdIT work. In the table below, we noted the percentage of our evaluators who selected each evaluation option. In aggregate, model outputs received high ratings across all languages. Model feedback for English, German, Chinese, and Spanish was the most positive. Quality was lower for Arabic, which we believe results from relatively lower-quality training data for that language. Accuracy suffered for Chinese, Japanese, Korean, and Spanish, and we still have to work to improve performance for these languages.
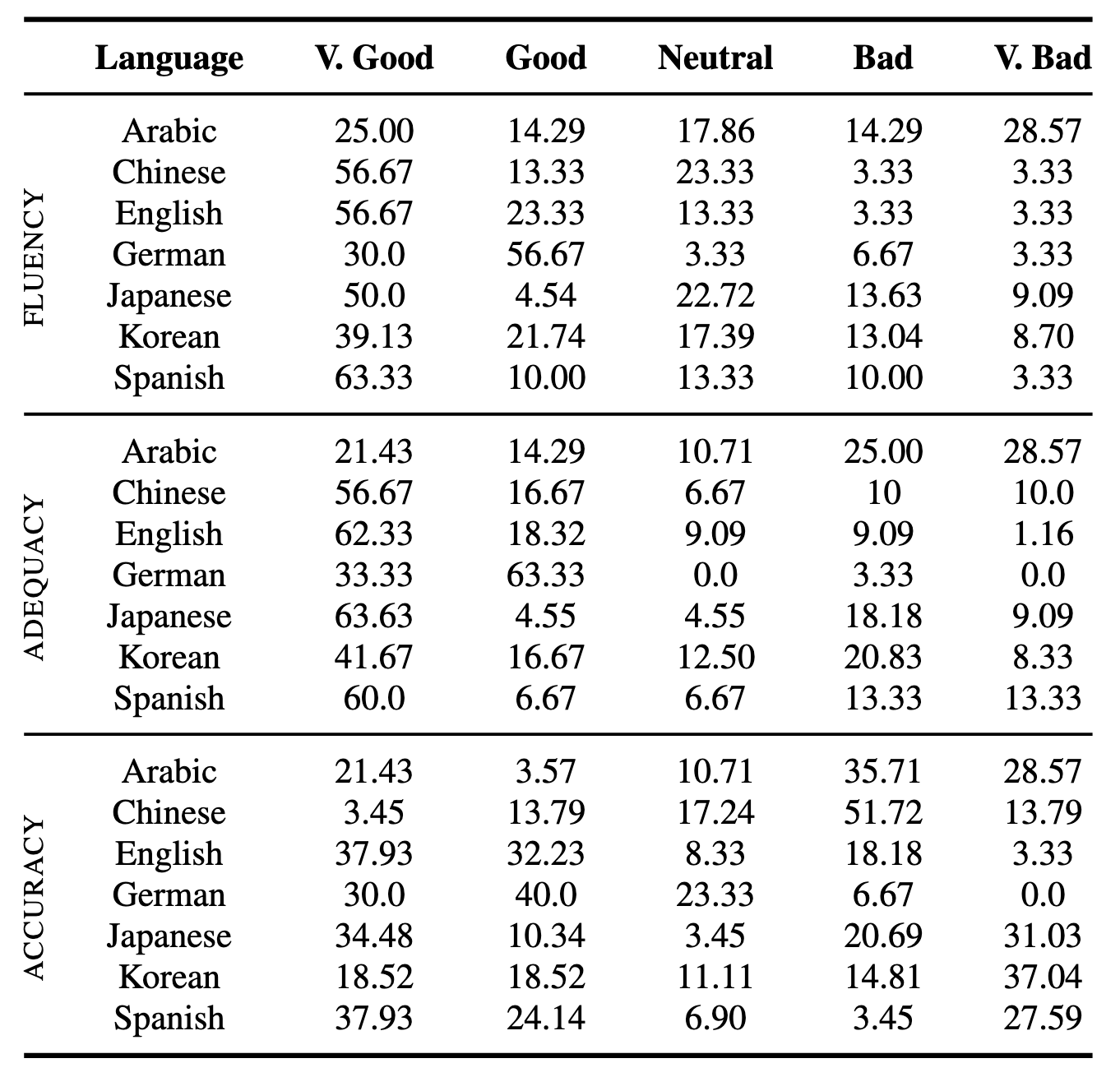
Table 2: Percent frequency for each feedback category received from human evaluators, aggregated by language
What’s next?
With mEdIT, we’ve shown that LLMs can accept edit instructions in one language and perform those edits in several other languages. With careful fine-tuning, these LLMs perform much better than all other models built to date. Positive feedback from human evaluators suggests that mEdIT will help them perform edits at scale. The fine-tuned LLMs seem to generalize and work for languages and edit tasks they haven’t been specifically fine-tuned for. We’ve made our work and data publicly available in the mEdIT repository on GitHub and on Hugging Face to foster further inquiry into the topic.
There is a lot more work we might do next, to extend and build on mEdIT:
- We could support more than seven languages and six language families—but that depends on having high-quality training data for those languages.
- We saw the model start to generalize to languages it hasn’t seen, and those generalizations can be better studied since they can lead to more accessible and ubiquitous writing assistants.
- We evaluated a small set of edit tasks against superficial measurements of success. We could go broader and deeper with our evaluations and, for example, look at metrics for fluency, coherence, and meaning preservation.
With efforts such as the extension of CoEdIT into a multilingual mEdIT, we hope to go beyond our core products and contribute to our mission of improving lives by improving communication.
If that mission and solving problems like these resonate with you, then we have good news: Grammarly’s Strategic Research team is hiring! We’re passionate about exploring and leveraging the potential of LLMs and generative AI to improve writing and communication for everyone. Check out our open roles for more information.
Note that Grammarly does not incorporate this research into its product today; while Grammarly is primarily focused on offering writing help in English, we’ve recently launched a translation feature for users of other languages.






