

In developing the world’s leading writing assistant, Grammarly helps people communicate wherever they write—whether in an engaging social media post, clear cover letter for a dream job, or anything in between. As we serve our mission of improving lives by improving communication, the challenge of grammatical error correction (GEC) remains a core focus. We’ve made tremendous progress toward building an AI-powered writing assistant that achieves state-of-the-art performance in correcting grammatical errors in English writing.
In the natural language processing (NLP) community, GEC is formalized as the task of correcting textual errors, such as spelling, punctuation, grammatical, and word choice. Historically, this has been formulated as a sentence-correction task: A GEC system takes a potentially erroneous sentence as input and must transform it into its corrected version. See the example below:

But more recently in the NLP research community, the preferred approach has become to treat GEC as a translation problem: A grammatically incorrect sentence is “translated” to its grammatically correct rewrite using neural machine translation–based (NMT) models. These models generally try to maximize n-gram or edit-based metrics. While they have achieved great success in their ability to transform grammatically incorrect texts to their corrected forms with n-gram precisions optimized, they don’t necessarily lead to high-quality corrections. For example, they might make changes to some other parts of the text, resulting in grammatically correct, albeit semantically inconsistent, text.
We explored an approach to GEC that avoids such issues: employing generative adversarial networks (GANs). GANs provide a framework that can be leveraged to directly model the task and try to generate not only a grammatical correction but also a more contextually appropriate suggestion for a given sentence. We describe this in a new paper from the Grammarly research team that was presented at the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP).
A short introduction to GANs
GANs are generative models that were introduced in 2014 by Ian J. Goodfellow and several colleagues. In a GAN framework, two neural networks—referred to as the generator and the discriminator—engage in a zero-sum game. The generator tries to produce data that typically comes from some ground-truth probability distribution. On the other hand, the discriminator learns to distinguish whether a given input is sampled from the ground truth or the generator’s artificially generated distribution. In order for the generator to effectively learn to trick the discriminator—by progressively producing high-quality outputs—we set up “adversarial” training between them. In summary, the game is set up as follows:
- The generator tries to create outputs that the discriminator will mistake as ones belonging to the real-world distribution.
- The discriminator tries to distinguish the generator’s output from the real-world output.
In the ideal adversarial setting, the learning of the framework reaches a saddle point: The generator would capture the general training data distribution. As a result, the discriminator would always be unsure of whether its inputs are real or not.
In the context of NLP, GANs have shown a remarkable ability to generate coherent and semantically meaningful text in many tasks, such as summarization, translation, and dialogue understanding.
What we did
We proposed a GAN-based generator-discriminator framework for grammatical error correction. There, the generator is a sequence-to-sequence (seq2seq) model, which is trained to “translate” a grammatically incorrect sentence to its grammatically correct rewrite. Most GAN architectures typically use a single-sentence “real-versus-fake” classifier as the discriminator. However, we argued that such a formulation does not accurately express the GEC task objective. We instead proposed the discriminator as a sentence-pair classification model, which is trained to evaluate the probability that the generated sentence is the most appropriate grammatically correct rewrite of a given input sentence.
Adversarial training between the two models was set up as optimizing a min-max objective. The discriminator learned to distinguish whether a given input is sampled from the ground truth (human-generated) or generator (artificially generated) distributions, and maximizes the difference between them. At the same time, the generator learned to trick the discriminator by producing high-quality correction candidates, thus minimizing the difference between its output and a ground-truth corrected sentence. Furthermore, the discriminator fine-tuned the generator using a policy gradient, which rewarded high-quality generated text when conditioned on the source. This improved the generation results. By minimizing the difference between the human- and the artificially generated distributions, we aimed at directly optimizing the task based on the criteria mentioned above.
In our framework, the discriminator was the more critical component—it was responsible for providing the appropriate reward to the generator based on the quality of the generated text. A conventional single-sentence real-versus-fake discriminator would provide the probability of a sentence being grammatically correct as the reward to the generator. We found that it was harder for such a classifier to differentiate between a ground-truth correction and a generated sentence that (a) did not make the intended corrections, or (b) changed the semantics of the source.
Based on this, we proposed the discriminator’s objective as being twofold.
1 To be able to evaluate the quality of the generated text in terms of its validity compared to the ground-truth distribution (by asking: Does the generated sentence match the ground-truth distribution?).
2 To quantify its quality as the appropriate rewrite for a given input sentence in the form of a reward given to the generator (providing high rewards to better corrections and penalizing low-quality corrections).
In summary, instead of only distinguishing between real-versus-fake sentences, the discriminator needed to measure the degree of “grammatical correctness” of an output sentence given its corresponding input sentence. We verified these hypotheses by experimenting with multiple discriminator formulations: single-sentence, sentence-pair, and GLEU (a widely used GEC evaluation metric).
What we found
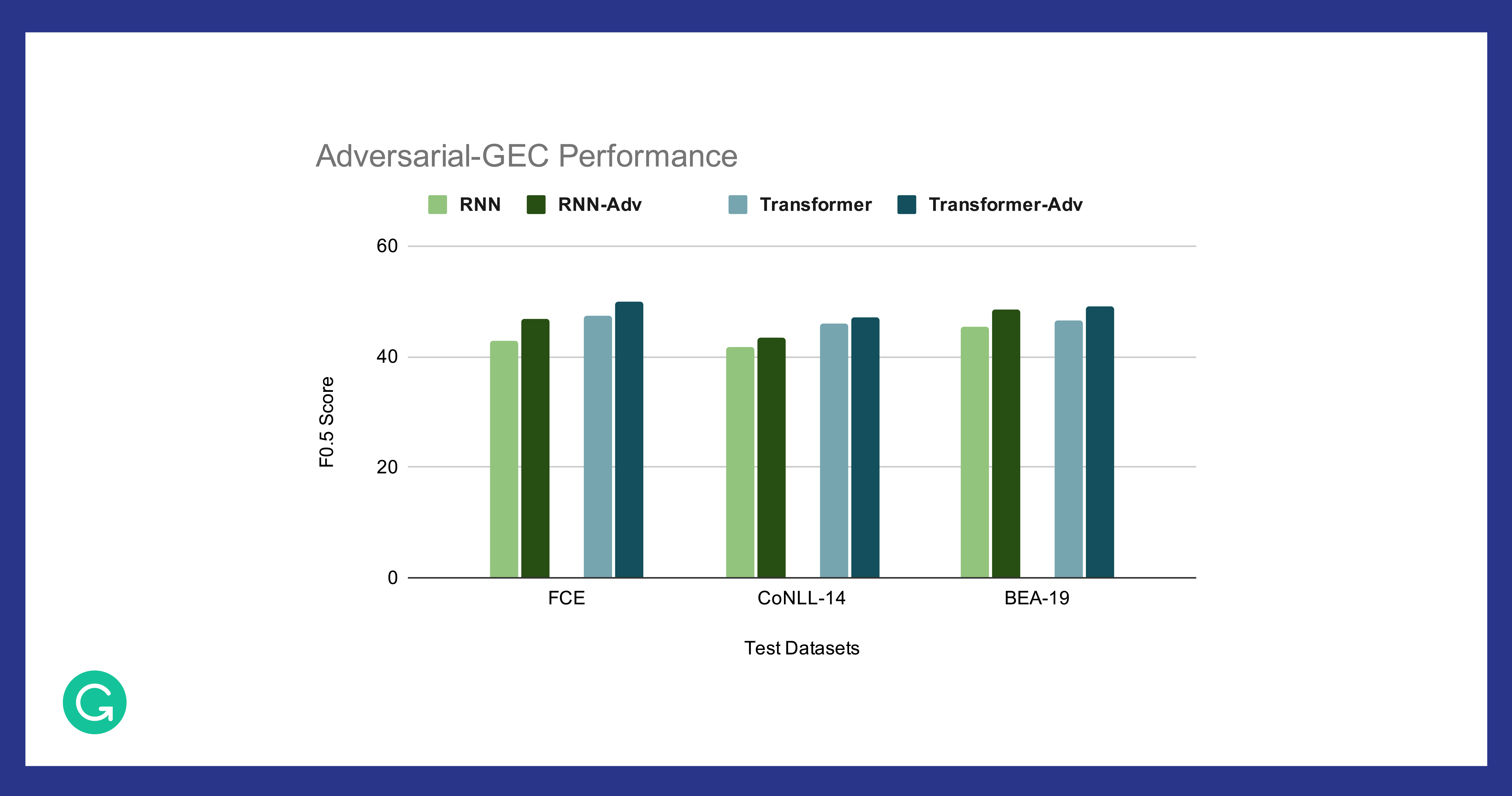
We experimented with two popular types of generators: RNN (attentional encoder-decoder) and transformer. We found that their adversarially trained analogues (RNN-Adv and Transformer-Adv) using the proposed framework consistently achieved better results on standard evaluation datasets for GEC, as shown in the figure below.
The following is an example of an incorrect sentence with its corrected rewrites generated by various models. In this particular case, it was the transformer-based, adversarially trained model (Transformer-Adv) that struck the best balance between grammatical correctness, meaning, and natural-sounding phrasing.

We also found that since the sentence-pair discriminator was able to access the contextual information about what has been corrected, it was able to better differentiate between low-quality or unsuitably corrected sequences and better understand semantic deviations in the generated corrections. Due to the adversarial training, the model dynamics were able to grow adaptively via a more appropriate task-specific reward (rather than a fixed metric based on n-grams), resulting in better distributional alignment. This led to much better performance compared with the conventional single-sentence real-versus-fake discriminator, or using the GLEU score directly as a discriminator reward.
A significant portion of our effort also went into making the framework perform well for the GEC task, which was the main focus of our experimentation. Please refer to our paper for more details.
Pushing the boundaries of GEC
In this work, inspired by GEC’s successes in other NLP areas, such as machine translation, abstractive summarization, and dialogue systems, we applied a rather challenging but perceptive approach to GEC. While policy-gradient methods have a long way to go in terms of generating high-quality, coherent texts, their success in other fields of AI, such as robotics and computer vision, continues to inspire their use in NLP. Promising results on various tasks across multiple datasets and domains demonstrate this.
In the future, we plan to improve the task-specific framework and training techniques based on recent state-of-the-art methods. This work is a similar step in exploring a new approach for this task. There’s always a chance these methods don’t always succeed—but often, they lead to interesting findings and results. At Grammarly, the challenge is just another step toward exploring innovative, impactful ways of building the world’s best AI-powered writing assistant.
NLP research forms the foundation of everything we build at Grammarly. If you’re interested in joining our research team and helping millions of people around the world wherever they write, get in touch—we’re hiring!
Vipul Raheja and Dimitris Alikaniotis are applied research scientists at Grammarly. They presented this research at the 2020 Conference on Empirical Methods in Natural Language Processing, held November 16–20, 2020. The accompanying research paper, titled “Adversarial Grammatical Error Correction,” appeared in the Proceedings of the Findings of EMNLP.






