

The natural language processing (NLP) research community has traditionally focused on the English language, but in just the past few years, there’s been an encouraging trend toward building models that work for other languages. Whether they are “multilingual” or trained for a specific language other than English, these models can help extend the reach of NLP intelligence to more people around the world. The applications range from transcription to translation to providing writing assistance that helps people communicate better—in whatever language they use.
Lack of data has historically been the main barrier to developing models in more languages. For many languages, well-curated and annotated public datasets for NLP simply do not exist. To help with this effort, Grammarly has released UA-GEC: the first dataset for grammatical error correction (GEC) and fluency correction for the Ukrainian language. It is freely available online and contains 20,715 sentences annotated for grammatical and fluency-related errors. UA-GEC joins the growing ranks of datasets for mid- and low-resourced languages such as German, Czech, Spanish, and Romanian.
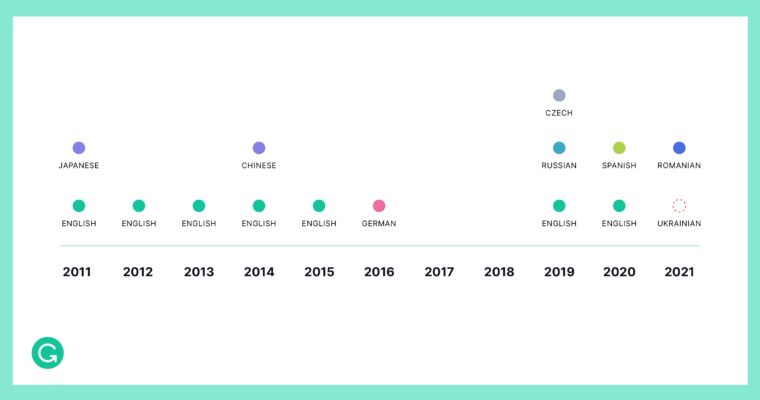
This chart shows public GEC datasets, when they were released, and which languages they cover.
What is a GEC dataset?
In NLP research, GEC is the task of automatically detecting and correcting grammatical errors in text (which includes spelling and punctuation). Fluency correction is an extension of GEC. Fluency edits are usually broader sentence rewrites that make the resulting text sound more natural to a primary speaker of the language.
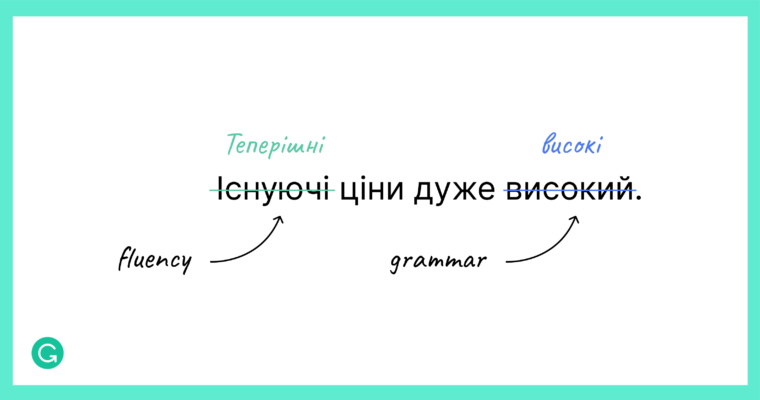
A sample Ukrainian sentence has been annotated for fluency and grammar corrections.

Here is the same annotated sentence in English.
The quality of English GEC has significantly improved over the past decade. Scores on the publicly available benchmark CoNLL-2014 rose from 37.3 in 2014 to 66.5 in 2020 (see the work by our colleagues: Omelianchuk et al., 2020). This success wouldn’t be possible without linguistic resources. Machine learning models that perform GEC and fluency edits rely on GEC datasets for training and evaluation.
A GEC dataset like UA-GEC is a collection of texts, where each text comes in two versions: (1) the original text with errors and (2) the annotated text with the errors identified. Language experts help develop these datasets by making annotations, which categorize the errors that appear and describe how they can be corrected.
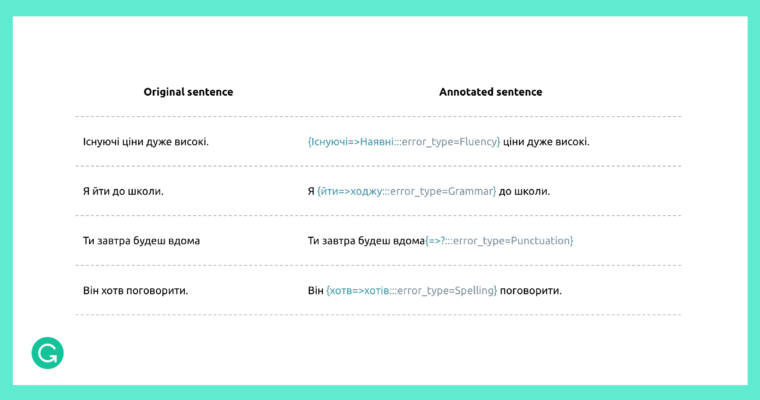
To illustrate what the UA-GEC dataset looks like, here is a sample we’ve taken directly from the data.

Here is the same sample from UA-GEC, translated into English.
There are multiple GEC datasets for English. Some of them aim to make a minimal set of edits to correct grammar; others allow for broader rewrites to correct fluency. But historically, many languages, including Ukrainian, haven’t had any publicly available GEC datasets.
Why Ukrainian?
Grammarly’s founders are Ukrainian, and many of our team members are from Ukraine. So you could say we know a thing or two about the language!
Ukrainian also presents some interesting challenges for NLP. One of these is its rich morphology. Take an English word like “see.” It comes in five forms based on tense, called conjugations: see, sees, saw, seen, and seeing. In contrast, the Ukrainian verb “бачити” (“to see”) has twenty-six possible forms! Knowing which word form to use depends on the tense (past, present, future), grammatical gender (“he saw” vs. “she saw” vs. “it saw”), person (“I see” vs. “she sees” vs. “they see”), and a multitude of other parameters.
With a much higher number of word forms than English, Ukrainian can be harder to model because, by default, a computer doesn’t understand that word forms are connected. To a machine learning model that has just started training, the words “see” and “saw” are just as different as “see” and “avocado.” Eventually, the model will learn the relationship between word forms, but this requires time and data—or special linguistic rules.
Also unlike English, Ukrainian is a synthetic language, which, unlike an analytic language, means its word inflections express syntactic relationships. It also admits a free word order: In most cases, words in sentences can be easily rearranged since inflections convey the grammatical meaning—i.e., endings point to the grammatical features of words (gender, number, etc.) as well as how they are related to the neighboring words in a sentence. This makes Ukrainian GEC or fluency correction more difficult, because there are so many potentially valid ways to rewrite a sentence.
Data collection
Building a GEC dataset happens in two steps: To begin, we collect texts that contain errors; next, we correct and annotate those mistakes. The first question is: Where do we get texts with errors?
One common approach is to use essays written by language learners. For some examples, see CLC FCE (English) and COWS-L2H (Spanish). Those corpora indeed contain a lot of mistakes. However, there are drawbacks to this strategy. Compared to those writing in their primary language, students learning a new language typically make different kinds of mistakes when writing—and more of them. The essay prompts often cover only a small amount of predefined topics, which tends to limit the vocabulary that appears in the data. And the very definition of “essay” restricts the writing to a certain tone and level of formality that isn’t representative of most communication tasks.
Another approach for collecting data is to sample sentences from random internet pages. This was done in the recently published CWEB dataset, for instance. However, web page content is often written by professional writers and/or is additionally proofread, so it doesn’t contain a sufficient number of errors. There are also many legal complications that can arise when using web data.
We wanted our data to contain mistakes that people typically make in their everyday writing. We also wanted our data to be as diverse as possible, representing a wide vocabulary and broad range of communication scenarios. To achieve this, we set up a data collection page and distributed it among online communities across the Ukrainian-speaking community. The page prompted volunteers to complete one of the following tasks:
1 Translate a short fragment of text from a foreign language into Ukrainian.
This task emulated so-called L1 interference; that is, mistakes that people make under the influence of another language. An example of such errors is what is referred to as “false friends,” which are words in different languages that sound and appear to be the same but have very different meanings. It’s important to have data on these common mistakes in order to provide writing suggestions for multilingual users.
2 Write a message on one of twenty provided topics.
The suggested topics helped people come up with ideas on what to write. We tried to choose topics that were diverse and realistic. For example, one of the topics involved writing a letter of complaint to a restaurant owner; another asked the volunteer to describe a party to a friend.
We asked people not to proofread their texts and not to make artificial errors, either.
3 Submit original writing (from anywhere), ideally without proofreading.
We invited people to submit a variety of texts that they’ve written. The data collection page remains active through 2021, and at the time of this article’s publication, 670 people have contributed.
The distribution of task choices is as follows:
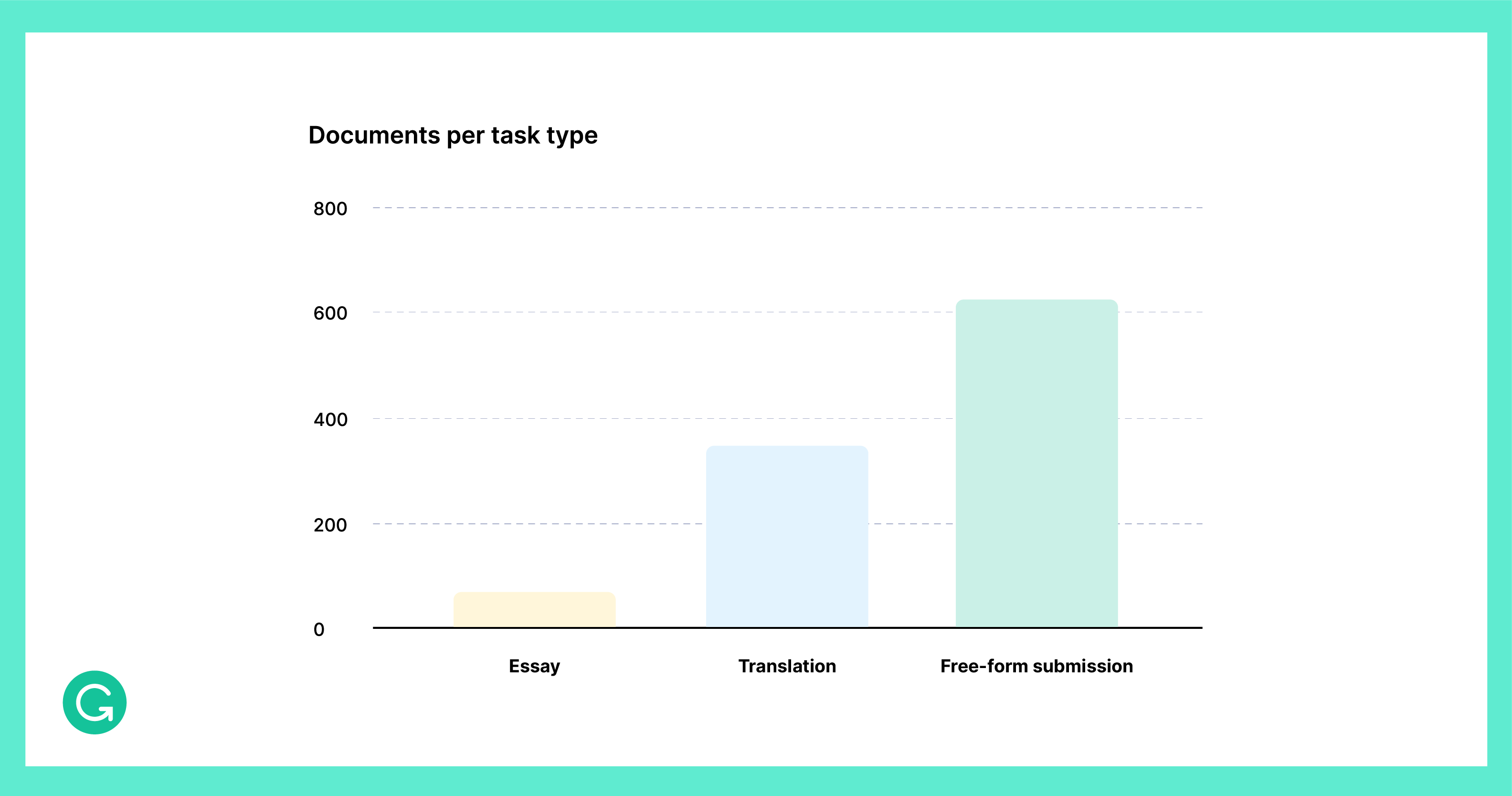
As you can see, most people chose the third task, submitting their own texts. This is a great thing! User-contributed texts have a very wide range of styles and genres, ranging from casual social network chats to formal and creative writing. The contributed texts are very diverse. They represent real-life writing much better than artificially constructed writing assignments.
Data annotation
We recruited two professional Ukrainian proofreaders. Their task was to correct texts and categorize error categories. Correcting texts meant rewriting a sentence to make it grammatically correct and fluent: I likes it. becomes I like it.
Categorizing errors meant taking an edit (likes becoming like in the example above) and classifying it per one of the following error categories: grammar, spelling, punctuation, or fluency. This information can be used later for finer-grained analytics. For example, we can answer questions like “Do secondary language speakers make more spelling mistakes than primary language speakers?”
Categories are also helpful when training models to correct only some error types and not the others. Reducing the scope makes the task more manageable—correcting punctuation alone is much easier than correcting all grammar. This is useful in teaching NLP: Students get the opportunity to work on a simpler version of the task.
The fluency category is a tricky one because it’s highly subjective: More often than not, two language experts won’t make the same fluency correction to a text. This subjectivity makes it a difficult category for a model to learn. For this and other reasons, researchers may sometimes want to exclude fluency and focus on grammar exclusively. Our data annotation scheme allows that as well.
Statistics
By now, we have collected and annotated 1,011 texts (20,715 sentences and 328,779 tokens) written by 492 unique contributors. If you printed out UA-GEC, you would get a book of around 800 pages—longer than Ulysses by James Joyce (which has approximately 265,000 words) and three times larger than Taras Shevchenko’s Kobzar!
You can find more detailed statistics and analysis in the accompanying paper.
For more context, here is a table showing some of the public GEC datasets that exist across various languages:
| Language | Corpus | Number of Sentences |
| English | Lang 8 | 1,147,451 |
| NUCLE | 57,151 | |
| FCE | 33,236 | |
| W&I+L | 43,169 | |
| JFLEG | 1,511 | |
| CWEB | 13,574 | |
| Czech | AKCES-GEC | 42,210 |
| German | Falko-MERLIN | 24,077 |
| Romanian | RONACC | 10,119 |
| Spanish | COWS-L2H | 12,336 |
| Ukrainian | UA-GEC | 20,715 |
Release
We released UA-GEC data on GitHub: https://github.com/grammarly/ua-gec.
Additionally, we released a Python package that simplifies processing annotated text files. This package already includes all the data and may be installed and used just like any other Python package. Refer to its documentation for more details.
Finally, we have published a paper draft that gives more technical details. The paper can be cited as follows:
@misc{syvokon2021uagec, title={UA-GEC: Grammatical Error Correction and Fluency Corpus for the Ukrainian Language}, author={Oleksiy Syvokon and Olena Nahorna}, year={2021}, eprint={2103.16997}, archivePrefix={arXiv}, primaryClass={cs.CL}}
What’s next?
The second version of UA-GEC is under development. We extended the data collection period through 2021, and expect the new dataset to be twice as large as the first.
We hope that UA-GEC will become a useful resource for the NLP community and will contribute toward robust multilingual research and modeling. The dataset is available under a CC BY 4.0 license at https://github.com/grammarly/ua-gec.
If these types of NLP problems sound interesting to you, we are currently hiring applied research scientists, machine learning engineers, and many other roles at Grammarly. Check out our jobs page for opportunities to help millions of people around the world communicate with one another.






