
At Grammarly, we have a lot of data at our disposal: frequency and type of errors, user behavior, the amount of text sent for processing, etc. This data allows us to test and improve our performance. However, managing data is extra work—often the location and format of the data are not suitable for immediate consumption. In data-driven companies like ours, it is very common to create information reshaping pipelines, conventionally called ETL (Extract, Transform, Load), which do literally what it says—grab the data in one place, modify it, and put it in another place.
This post focuses on one particular ETL pipeline developed by our team. The task was to parse 200-something gigabytes of compressed JSON logs, filter relevant entries, do some data massaging, and finally dump the results into an SQL database. Repeat daily. Before our team took over this pipeline, it was implemented with Apache Pig run on top of Hadoop. Hadoop and other distributed computation systems are perfect for ETL tasks because the problems are often embarrassingly parallel and thus scale wonderfully by just adding extra computing nodes. However, we decided to redo the solution in a single-machine setup for the following reasons:
- It is much easier to reason about a program running on a single machine rather than a cluster of machines executing some unpredictably scheduled workload.
- New requirements were introduced that would require parallel workers to have a consistent view of one small piece of state. Again, this is a lot simpler to implement in a standalone program.
- The whole pipeline running in one place means that we can connect to it via remote REPL and get the full power of interactive development and introspection while debugging and tuning the parameters.
- We can run the pipeline on the machine where the database lives to reduce the amount of traffic traveling across the network and improve the speed of the pipeline.
- Last but not least, this saves us some cash. We run the pipeline during non-working hours when the database is minimally used; the beefy instance that hosts the database is idle at that time.
Now that our motivation is clear, let’s jump straight to the action. In this post, we provide dummy functions that do roughly the same work as our real processing functions in terms of time, so it should be possible for you to follow along and better understand the problems that we faced.
Base functions
To begin with, we need a dummy file that will pretend to be a data source. Let’s forget about the gzip part for now and just create a file with 100,000 random JSON objects:
(require '[clojure.java.io :as io]
'[cheshire.core :as json])
(letfn [(rand-obj []
(case (rand-int 3)
0 {:type "number" :number (rand-int 1000)}
1 {:type "string" :string (apply str (repeatedly 30 #(char (+ 33 (rand-int 90)))))}
2 {:type "empty"}))]
(with-open [f (io/writer "/tmp/dummy.json")]
(binding [*out* f]
(dotimes [_ 100000]
(println (json/encode (rand-obj)))))))This code should generate a ~30MB file. Now let’s create a reverse function that will parse this file:
(defn parse-json-file-lazy [file]
(map #(json/decode % true)
(line-seq (io/reader file))))
(take 10 (parse-json-file-lazy "/tmp/dummy.json"))line-seq reads the provided stream, going line by line into a lazy sequence, which we then lazily parse using the JSON parser. It is important to note that we cannot just load all the data at once and then write it to the database; it simply won’t fit into the memory. We need an approach that operates on streams of data piecewise. We start with a lazy solution here because that’s what we did initially, and because it is easy to experiment with in the REPL.
(defn valid-entry? [log-entry]
(not= (:type log-entry) "empty"))
(defn transform-entry-if-relevant [log-entry]
(cond (= (:type log-entry) "number")
(let [number (:number log-entry)]
(when (> number 900)
(assoc log-entry :number (Math/log number))))
(= (:type log-entry) "string")
(let [string (:string log-entry)]
(when (re-find #"a" string)
(update log-entry :string str "-improved!")))))
(->> (parse-json-file-lazy "/tmp/dummy.json")
(filter valid-entry?)
(keep transform-entry-if-relevant)
(take 10))We’ve written two new functions. One is for filtering out invalid entries. The other does filtering and transformation at the same time and is intended to be applied with keep.
The last stage of the pipeline is saving data into the database. We don’t want to perform INSERT on each entry separately, so we write it as a function that takes a batch:
(def db (atom 0)) ; Dummy "database"
(defn save-into-database [batch]
(swap! db + (count batch))) ; Simulate inserting data into database.Finally, we expect the top-level process function to accept multiple files. With this and all other considerations in mind, we define this function:
(defn process [files]
(->> files
(mapcat parse-json-file-lazy) ; mapcat b/c one file produces many entries
(filter valid-entry?)
(keep transform-entry-if-relevant)
(partition-all 1000) ; Form batches for saving into database.
(map save-into-database)
doall)) ; Force eagerness at the end.Great, our primary processing function is ready! Let’s try it out:
(time (process ["/tmp/dummy.json"]))
;; "Elapsed time: 2472.854294 msecs"
(time (process (repeat 8 "/tmp/dummy.json")))
;; "Elapsed time: 33295.152823 msecs"Looks weird, right? Processing eight files appears to be sixteen times slower than just one file. But if we look at our application through a profiler (e.g., Java VisualVM), it becomes apparent that the processing of one file doesn’t run long enough for the garbage collector to kick in. At eight files, the GC is quite active and slows down the rest of the VM. (Note: We did this benchmark using Concurrent Mark Sweep Collector. With other GCs, the behavior can be different.)
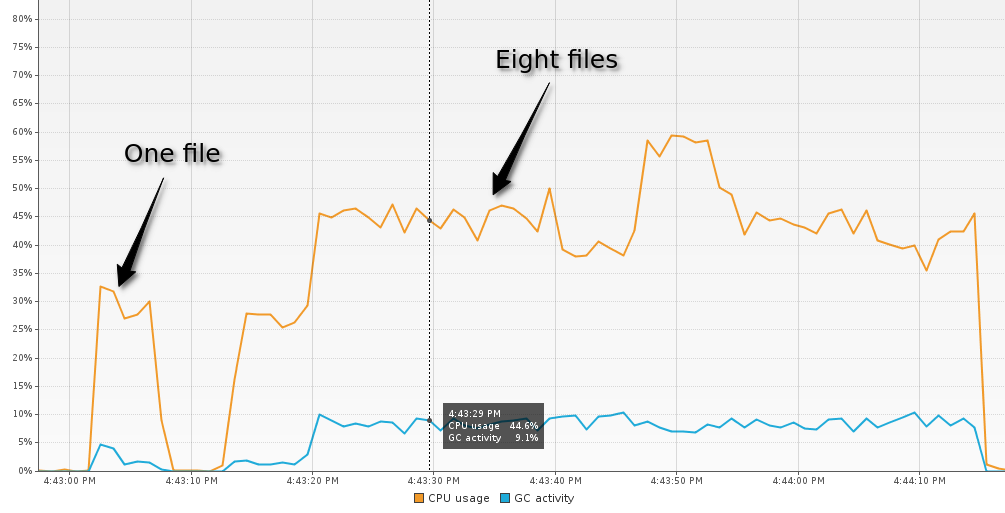
Anyway, the first iteration of our ETL pipeline is now complete. Is it any good? Yes! It is very straightforward, it’s convenient to test each step separately, and it’s easy to add new steps. But there are a couple of shortcomings, too:
- Lazy approach puts a serious strain on the garbage collector. At each step of our pipeline, we are creating transitional lazy sequences that we don’t really need.
- It is unclear how to parallelize this pipeline. Yes, Clojure has
pmap, but where exactly should we put it? When mapping over files? When writing into the database? Again, laziness doesn’t help here—because it obscures the place where the operations are actually being executed.
Turns out that it is possible to deal with these issues while keeping the pipeline clean and composable, and with minimal effort.
Enter transducers
Transducers were introduced into Clojure with version 1.7. A great starting point for learning transducers is to watch two talks by Rich Hickey: Transducers and Inside Transducers. In simple terms, a transducer is an abstraction that allows you to compose stream-operating functions with almost no overhead. For example, the following two expressions are equivalent, but the latter doesn’t create an intermediate sequence between filtering and mapping:
(map inc (filter even? ))
(sequence (comp (filter even?) (map inc)) )This post doesn’t go into detail about how transducers work—in addition to the above-mentioned videos, there are other great tutorials on the internet. We will just assume that you already have basic familiarity with them.
We begin by transducifying the first step—parsing JSON files. We need a function like line-seq, but that will return something reducible instead of a lazy sequence.
(defn lines-reducible [^BufferedReader rdr]
(reify clojure.lang.IReduceInit
(reduce [this f init]
(try
(loop [state init]
(if (reduced? state)
state
(if-let [line (.readLine rdr)]
(recur (f state line))
state)))
(finally (.close rdr))))))To be honest, this is a somewhat advanced usage of the transducers machinery. You rarely have to write functions like this or deal with low-level Clojure interfaces. This function takes a Reader object and returns an object that can reduce itself by calling the provided reducing function on each line it reads. Notice also the call to reduced?. It allows the reduction to terminate early if the underlying transducer (like take, for example) said it doesn’t want any more values.
Now we are able to write a new non-lazy parsing function:
(defn parse-json-file-reducible [file]
(eduction (map #(json/decode % true))
(lines-reducible (io/reader file))))Here we first create a reducible object from a file and then attach a parsing transducer to it by using eduction. You can think of eduction this way: you have a stream of values, and now you modify the values in the stream with a function, but no values are being realized yet. eduction returns a recipe for the values to come.
This is all the preparation we need to write our improved process function.
(defn process-with-transducers [files]
(transduce (comp (mapcat parse-json-file-reducible)
(filter valid-entry?)
(keep transform-entry-if-relevant)
(partition-all 1000)
(map save-into-database))
(constantly nil)
nil
files))A lot is going on in there, so let’s take this function apart. The first thing you can see is the (comp ...) block, which looks just like the threaded form from the lazy implementation. The transducer returned by this form assumes that its input is the stream of file names, and on the output side, it does nothing (but modifies the database with side effects in the last step). To run this transducer, we call transduce, which is just like reduce but supports transducers. Since we are not interested in the output values from the pipeline, we stub the accumulator function with (constantly nil).
(time (process-with-transducers ["/tmp/dummy.json"]))
;; "Elapsed time: 1976.104034 msecs"
(time (process-with-transducers (repeat 8 "/tmp/dummy.json")))
;; "Elapsed time: 16552.3194031 msecs"Processing of a single file got only marginally faster, but we see a substantial improvement when running the pipeline over multiple files. The GC is not so mad at us anymore, and the execution time scales consistently with the number of files (2 sec * 8 ≈ 16.5 sec).
Furthermore, we can parallelize this solution using Clojure’s core.async. This library includes a function called pipeline, which uses transducers to perform parallel transformation of values from one channel into another. Here comes the parallel implementation:
(require '[clojure.core.async :as a])
(defn process-parallel [files]
(a/<!!
(a/pipeline
(.availableProcessors (Runtime/getRuntime)) ;; Parallelism factor
(doto (a/chan) (a/close!)) ;; Output channel - /dev/null
(comp (mapcat parse-json-file-reducible) ;; Pipeline transducer
(filter valid-entry?)
(keep transform-entry-if-relevant)
(partition-all 1000)
(map save-into-database))
(a/to-chan files)))) ;; Channel with input dataWe replaced the reducing function transduce with pipeline. The first argument it takes is the parallelism factor—we set it to the number of cores our machine has. The next argument is the destination channel of the pipeline. Since we are still not interested in the output values, we provide it with a closed channel that is always able to accept values and just drops them on the ground. Next is our transducer, which is left unchanged from the previous function. The last argument is the channel with input values—here we convert the list of file names into a channel. Finally, pipeline itself returns a channel that will receive a value when the computation is complete, so we blockingly take out of this channel to wait for completion.
The last test:
(time (process-parallel (repeat 8 "/tmp/dummy.json")))
;; "Elapsed time: 8718.899154 msecs"Sweet! We got a 2x performance increase from running on four cores. We likely don’t see 4x improvement because the synchronization overhead is too significant in this toy example, and because GC (from parsing JSON objects) still eats CPU time. But if we open htop we can observe this pleasing picture:

Conclusion
The ecosystem of Big Data™ solutions is thriving, but sometimes your Data is not that Big. Sometimes you are in a spot where you can optimize your code just a little bit further to fit it on a single machine and get a much more predictable and maintainable solution. It’s better not to reach out for the distributed computation platform just because you can, but to investigate other possibilities beforehand.
Clojure is an excellent language for cases like this. It allows you to rapidly iterate on your experiments while writing high-performance code. REPL, value inspector, and tracer are invaluable when working with data. And being of JVM lineage, Clojure programmers gain access to modern profilers, robust libraries, and all in all a superb virtual machine.
We hope this write-up motivates you to try out Clojure and learn more about transducers—or simply satiate your interest in moving bytes around. In any case, thanks for reading, and may this information serve you well.






