

At Grammarly, it’s crucial that our diverse teams of researchers, linguists, and machine learning (ML) engineers have reliable access to the computing resources they need whenever they need them.
The responsibilities of every team are very different, and so are the infrastructure requirements needed to accomplish their goals:
- Analytical and computational linguists: focus on data sampling, preprocessing and post-processing, data annotation, and prompt engineering
- Researchers: work on model training and evaluation based on data and cutting-edge research papers
- ML engineers: deploy production-ready models into inference services, applying optimization techniques to find the best performance-versus-cost balance
Our legacy system was serving all of those needs, but it started struggling to keep up with the growing demand. This motivated us to start a project to reinvent our ML infrastructure at Grammarly. In this article, we’ll describe our path and the challenges we faced along the way.
Legacy system design and limitations
Our legacy ML infrastructure system had a simple design, and it served us well for nearly seven years.
The system comprised a simple web UI that provided an interactive interface for creating EC2 instances of a certain type and running predefined bash scripts to install the required software, depending on the use case. Then, all the required setup was done in a background process that applied a dynamically created Terraform state to create a ready-to-use EC2 instance.
As with any homegrown solution, it’s common to encounter unique bugs and unexpected behaviors that can be tricky to predict. For example, there was a time when the dynamic Terraform provisioning resulted in instances being provisioned twice. This created a challenge, as those duplicated instances weren’t tracked, used, or deallocated. This caused a significant waste of money until we discovered and resolved the issue.
Scalability was another key challenge we faced. When users needed more resources, our only option for scaling vertically was to offer larger instances. With the exciting LLM revolution, this challenge became even more pressing, as securing large instances in AWS could now take weeks! Moreover, since each EC2 instance was tied to the person who created it, this made resources even more scarce.
Besides scalability issues, there were other drawbacks:
- Support issues: Those long-running, personalized, stateful EC2 instances were hard to support properly and had less than 25% utilization on average.
- Technical limitations: Due to implementation details, the instances were restricted to a single AWS region and a limited set of availability zones, which complicated expansion and quick access to newer EC2 instance types.
- Security concerns: Security patching and aligning with the newest requirements was a challenge.
Given the challenges and scope of work required to address them in the legacy system, we concluded that the time was right for more radical changes.
Implementation of the new ML infrastructure
Once we decided to build an entirely new infrastructure, we sat down to list the system’s basic requirements. At its core, there are just three main parts: storage, compute resources, and access to other services.
Compute resources: One key change was moving from stateful, personalized EC2 instances to dynamically allocated compute clusters on top of shared computing resources. We achieved this by moving from EC2 to EKS (Kubernetes environment), which allowed us to decouple storage from compute resources and move from personalized to dynamically allocated resources.
Storage: While EFS remained the main storage option in legacy systems, we moved from global shared storage to per-team EFS storage and provided S3 buckets as a more suitable option for certain use cases.
Access to other services: Instead of managing dozens of private links between different accounts, we centralized endpoint access under ICAP Proxy through which every request was routed.
One of the project’s core principles was to write as little code as possible and combine only open-source solutions into a working system.
In the end, our technical choices can be summarized like this:
- Kubernetes (K8s)—the core industry standard for compute abstraction
- Karpenter—a standard for dynamic provisioning of compute resources in K8s
- KubeRay—cluster compute orchestration framework
- Argo CD—K8s GitOps and CI/CD tool
- Python CLI / Service—a thin wrapper to allow users to interact with the system and manage their compute clusters
Let’s walk through how we used these tools.
How this all plays together
We use open-source technologies (K8s, Karpenter, Argo CD, KubeRay) for all deployments and orchestration. To make the system easily accessible to users, we use only simple custom client and server parts.
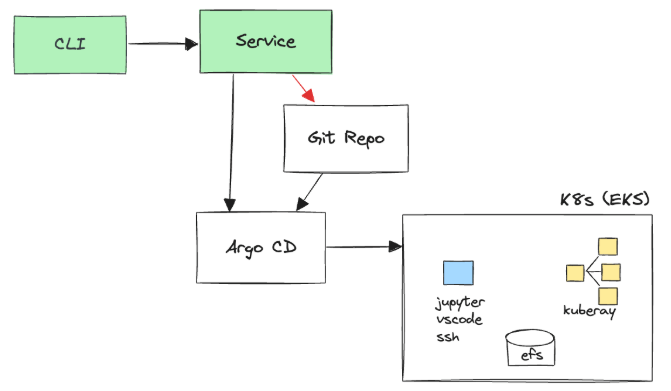
On user request, we have a service that commits Helm values to our Git repo and polls the Argo CD API to get the deployment’s status. Argo CD watches the configurations and automates the deployment to Kubernetes. Helm charts being deployed involve KubeRay (which provides cluster computing capability), JupyterLab, VS Code, and SSH servers (which provide different kinds of UI for users to interact with) as deployment options, depending on the use case.
This flow allowed us to offload complex operations like provisioning and status monitoring to open-source tools, so we don’t need any custom code for those functions.
Users workflow
With the new infrastructure, our users’ workflows have changed, but it also allowed to make them more efficient.
Now, users create a cluster that generates a YAML file template with all the resources it needs to allocate, which Docker images should be used, and what kind of UI it should provide.
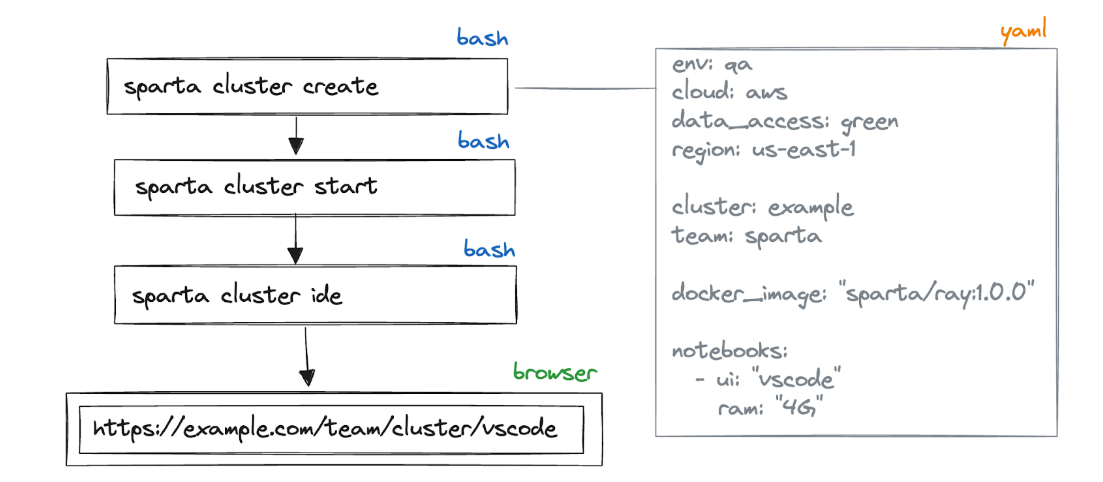
Afterward, they start the cluster, which opens a web UI in the browser or provides an SSH connection string.
Design and implementation challenges
Along the way, we ran into a few interesting design choices that we’d like to describe in detail.
The server commits to a remote Git repo
In the new system, the CLI pushes cluster config to the back-end service. However, the configuration should somehow be placed in the centralized configuration Git repository, where it can be discovered and deployed by Argo CD. Our design service directly pushes changes to a remote Git repo (GitLab in our case). We call this a GitDb approach, as we replace the database with a Git repository and push changes to it.
As with any system that becomes popular among users, we need to scale it out by adding new replicas. So now, multiple replicas of the service might concurrently push commits to the same remote Git branch. Basically, we can get into trouble with a classic distributed database write.
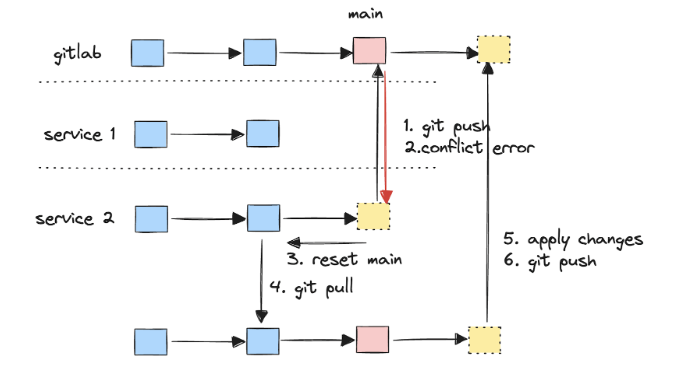
For example, if one service replica attempts to push to the GitLab main branch while another replica has already done so, a Git push conflict error will occur. Therefore, it is important to implement well-tested revert-and-retry logic, like the one in the picture.
Eventually, we needed to solve increasingly complex concurrency problems related to this design decision. We suggest simplifying such custom solutions as much as possible, resorting to more complex custom logic only when necessary.
Multiple Karpenter provisioners
Karpenter was used to scale our clusters up and down automatically. Considering the diverse needs of our team, we created specialized provisioners for each use case. It is also important to ensure that these provisioners do not conflict with one another, as conflicts could lead to suboptimal scheduling decisions.
There are three provisioners configured in our setup:
- The default provisioner serves CPU/RAM resource requests (i.e., non-GPU workloads).
- The GPU provisioner manages GPU resources, ensuring non-GPU workloads are not scheduled on costly GPU instances.
- The capacity reservation provisioner manages large resources and ensures smaller payloads won’t be scheduled for large instances.
Tight integration with capacity reservations
One of our core use cases is training and fine-tuning large language models (LLMs). We have a rapidly growing demand for large instance types (like p4de.24xlarge, p5.48xlarge), which are not reliably available in the on-demand market. Therefore, we extensively use AWS Capacity Reservations. We’ve built a comprehensive integration around it to clearly visualize the current use of the reservations and provide notifications on expiring reservations.
Adoption challenges
The project’s primary challenge was achieving user adoption. Motivation, feature parity, and tight timelines were the main factors in adoption.
We approached this on a case-by-case basis. We created a list of user stories to ensure that users were not simply migrating to a new tool but also gaining additional functionality. This changed the context of the migration for the teams and helped prioritize. We also managed to receive approval from senior management to make the migration a company-wide goal.
Another significant technical challenge for adoption was using Docker images and Kubernetes abstractions. Researchers are used to bare, stateful EC2 instances, so we needed to document and communicate the differences so that researchers felt comfortable again. We developed templates and CI automation to simplify Docker image creation, making it as easy as writing a custom bash script. Later, we also introduced initialization bash scripts to provide a shorter feedback loop and make the experience even more similar to the legacy system.
Benefits and impact
While implementing the project, we found it useful to make sure we ourselves and all the stakeholders understood the need for the project and that users saw value in migration to our new solution.
The most valuable and measurable outcomes of the project were:
- Linguists benefit from significantly reducing setup time: We saved them multiple hours per person per sprint.
- ML team members wait much less time for resources, as they can benefit from using a shared pool of large instance resources. Before, they needed to wait from a few days to 30 days for computing resources. Now, it’s reduced to zero time, as we enabled the planning and sharing of resource needs in advance.
- Our infrastructure became easier to patch and update to align with new requirements, making security stronger.
- Last but not least, we centralized our tooling around a single tool across different teams, which enabled the sharing of resources and expertise.
Closing thoughts
This project brought us numerous valuable insights along the way. If we were to start over, we would definitely give more attention to customer needs and pains with the current tooling from the beginning. The project was structured to be flexible and meet the users’ future needs; however, a more comprehensive list of requirements from the start would have helped us save considerable effort in adjusting. We would also avoid repeating the same mistakes made in the legacy system, such as increasing the complexity of the custom code base that supports the infrastructure. Additionally, we would proactively look for ready-to-use solutions to replace custom components.
Our conclusion at the moment is that completely replacing our ML stack with a SaaS solution would not precisely meet our needs and would reduce productivity. Having full control and a deep understanding of the entire system puts us in a strong position with our internal users, who chose this solution over other alternatives. Additionally, having extendable and replaceable components makes the setup more flexible. This is in contrast to out-of-the-box all-in-one solutions like KubeFlow or Databricks. That said, we constantly evaluate our tooling and adjust to the industry; we’re open to revisiting this in the future.
If you want to work on the frontier of ML and AI, and help the world communicate better along the way, check out our job openings here.






