
The original article on which this post is based was co-written with Joel Tetreault and Keisuke Sakaguchi. This post was written in collaboration with Sunshine Yin, a software engineer at Grammarly.
How do you know if your proofreading algorithm is doing a good job? So far, the NLP community has used the standard of “minimal edit corrections”—i.e., the minimal number of edits to make a sentence grammatically correct. However, the problem with this approach is that a grammatically correct sentence doesn’t always sound natural to a native speaker. For the past two years, we—Joel Tetreault, Courtney Napoles, and Keisuke Sakaguchi—have been tackling this problem. Joel is Grammarly’s Director of Research, and Courtney and Keisuke are both PhD students at Johns Hopkins Center for Language and Speech Processing.
Take the following incorrect sentence:
<code class="highlighter-rouge">they just creat impression such well that people are drag to buy it.</code>Using the “minimal edit” approach, the sentence would be corrected to:
<code class="highlighter-rouge">They just create an impression so well that people are dragged to buy it.</code>While this sentence is grammatically correct, no native speaker would ever say it. The “fluency edit” would look something like this:
<code class="highlighter-rouge">They just create such a good impression that people are compelled to buy it.</code>Here’s another:
| Original | From this scope, social media has shorten our distance. |
| Minimal edits | From this scope, social media has shortened our distance. |
| Fluent | From this perspective, social media has shortened the distance between us. |
Beyond “minimal edits”
We believe that the field should progress toward fixing grammatical errors (such as minimal edits) while making the sentence more native sounding (fluent). And we want to provide the NLP community with better tools to help advance this goal.
Sentence-correction algorithms need to be evaluated against a data set to test whether the algorithm works well. This data set should contain hundreds or thousands of grammatically incorrect sentences and a list of possible ways that each sentence may be corrected. These possible corrections are called “references.” Where would one obtain such a data set?
There are four well-known publicly available corpora of non-native English annotated with corrections:
- The NUS Corpus of Learner English (NUCLE), which contains essays written by students at the National University of Singapore that were corrected by two annotators using 27 error codes
- The Cambridge Learner Corpus First Certificate in English (FCE), which has essays coded by one rater using about 80 error types
- The Lang-8 corpus, comprising text from the social platform lang-8.com alongside user-provided corrections
- The AESW 2016 Shared Task corpus, which contains text from scientific journals corrected by a single editor
These data sets comprise ungrammatical sentences alongside their respective grammatical corrections. These parallel sentences are created by humans (such as English teachers), who are hired to annotate (i.e., correct) the sentences. Typically, annotators are instructed to change as little as possible about the sentences to make them grammatically correct. For example, they are usually instructed to highlight a span of incorrect text, assign a specific error to that span from a list of error types, and then type a correction to the span. Most existing data sets contain only one or two references for each wrong sentence (additional references are costly to generate), and these references contain only minimal edits.
While the minimal edits method has the advantage of focusing the annotation process, it is also problematic, as there are many ways to correct a sentence, and because minimal edits often don’t lead to natural-sounding sentences. If your algorithm tried to correct a sentence in a way that did not match one of the references, then it would be unfairly penalized.
Developing our own fluency edit dataset (JFLEG)
We decided to create a new method of evaluation that would focus on fluency edits instead of solely minimal edits. For this evaluation, we needed a data set of fluency edits, which didn’t exist. So we crowdsourced fifty English speakers through Amazon’s Mechanical Turk to annotate a data set. Each annotator had to pass a screening test to qualify. Candidates were asked to edit five sentences, which we manually reviewed. About a hundred people passed the screening, and fifty were chosen as annotators. This data set, which we call the Johns Hopkins University FLuency-Extended GUG corpus (JFLEG), contained about 1,500 sentences from an English proficiency exam, written by speakers of a diverse number of non-English languages. These sentences in their original form were not annotated, but each sentence was ranked, in a prior research effort, on a scale of 1 to 4 (least to most grammatically correct). Here is a comparison of our JFLEG test set with the leading grammatical error correction test set, CoNLL-14:

We asked the crowd-sourced annotators to correct these sentences. Instead of instructing the annotators to categorize errors using specific error tags (as in the minimal-edit approach), we simply asked them to correct each sentence so that it sounded natural. We also advised them to keep as much of the original sentence as possible. Each sentence was corrected by four annotators, meaning that each sentence would have four references. The chart below, which is based on a manual evaluation of 100 annotated sentences, shows the percentage of sentences containing each type of error, as well as the percentage of those errors that were edited by humans. Orthographic errors include errors in spelling, hyphenation, capitalization, word breaks, emphasis, and punctuation. Grammatical errors include errors in syntax, such as subject-verb agreement.
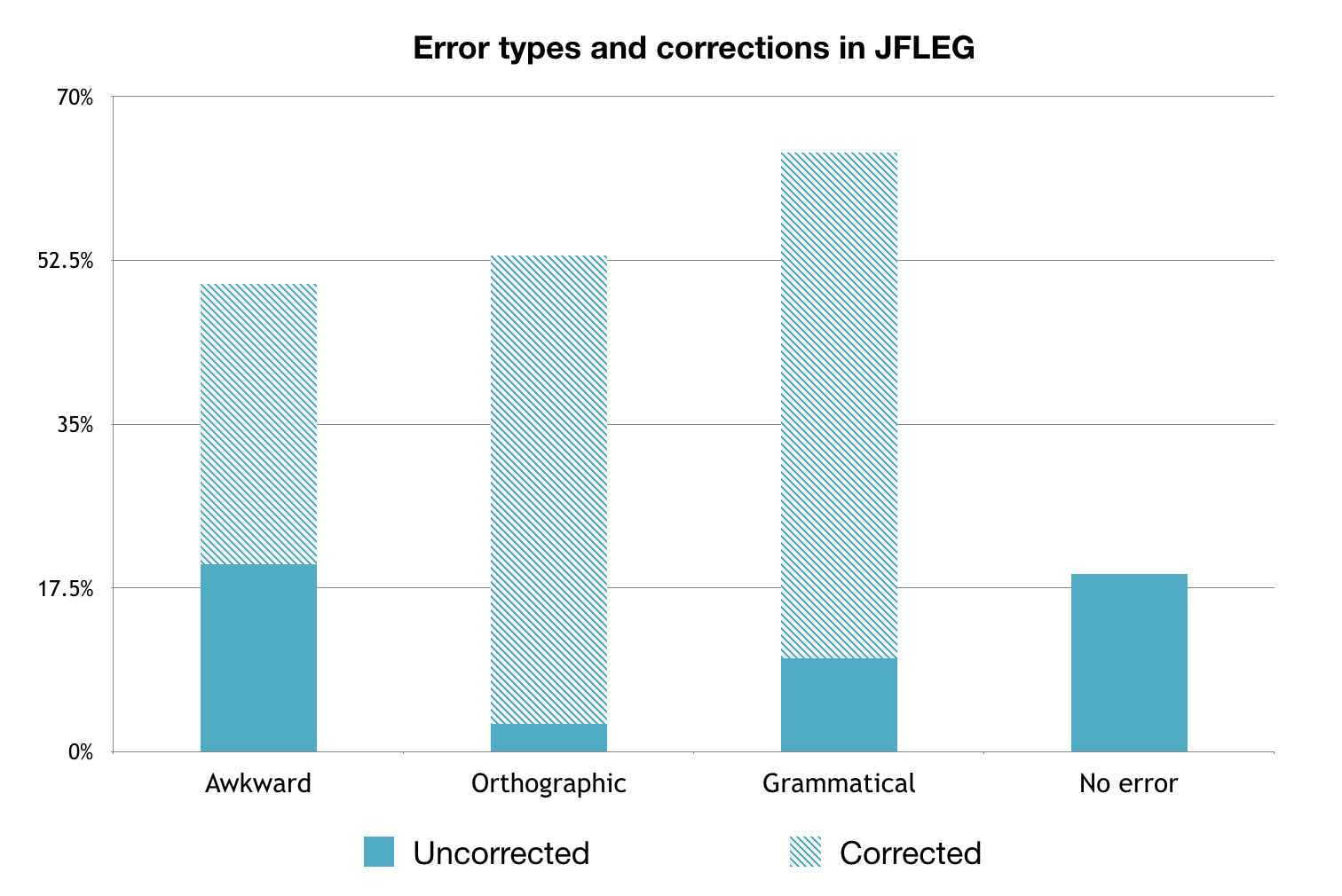
Notably, about 30% of corrections contained fluency edits, and about 60% contained only minimal edits, such as changes to verb number of prepositions. Here are some sentences from the JFLEG corpus, with the original, ungrammatical sentence and the human corrections of each:
| Original: | In today's Compuer skill is first important life skill. |
| Human 1: | In today's world Computer skills are the first important life skill. |
| Human 2: | Today, computer skills are the most important life skill. |
| Human 3: | In today's world, computer skills is the most important life skill. |
| Human 4: | Today, computer skills are the most important life skill. |
| Original | Since most urban areas are occupied with cars, they are all facing up with an irresistible problem of air and noise pollution. |
| H1 | Since most urban areas are occupied with cars, they are facing a problem of air and noise pollution. |
| H2 | Since most urban areas are congested with cars, they all face the terrible problem of air and noise pollution. |
| H3 | Since most urban areas are occupied with cars, they are all face upped with an irresistible problem of air and noise pollution. |
| H4 | Since most urban areas are teeming with cars, they are all facing the unavoidable problem of air and noise pollution. |
After the annotations were complete, we examined 100 sentences from the data set and categorized them by the types of errors the sentences contained.
What we found
The prior minimal-edit evaluation has identified the best systems for making minimal-edit corrections, but which systems are the best for making fluency edits? We applied our fluency-edit evaluation system to four leading academic systems (AMU, NUS, CAMB16, and CAMB14) by running them on the ungrammatical sentences from this data set.
The chart below, based on a manual evaluation of 100 sentences, shows the percentage of error types that remained after each system was run on this data set, as compared with the original.
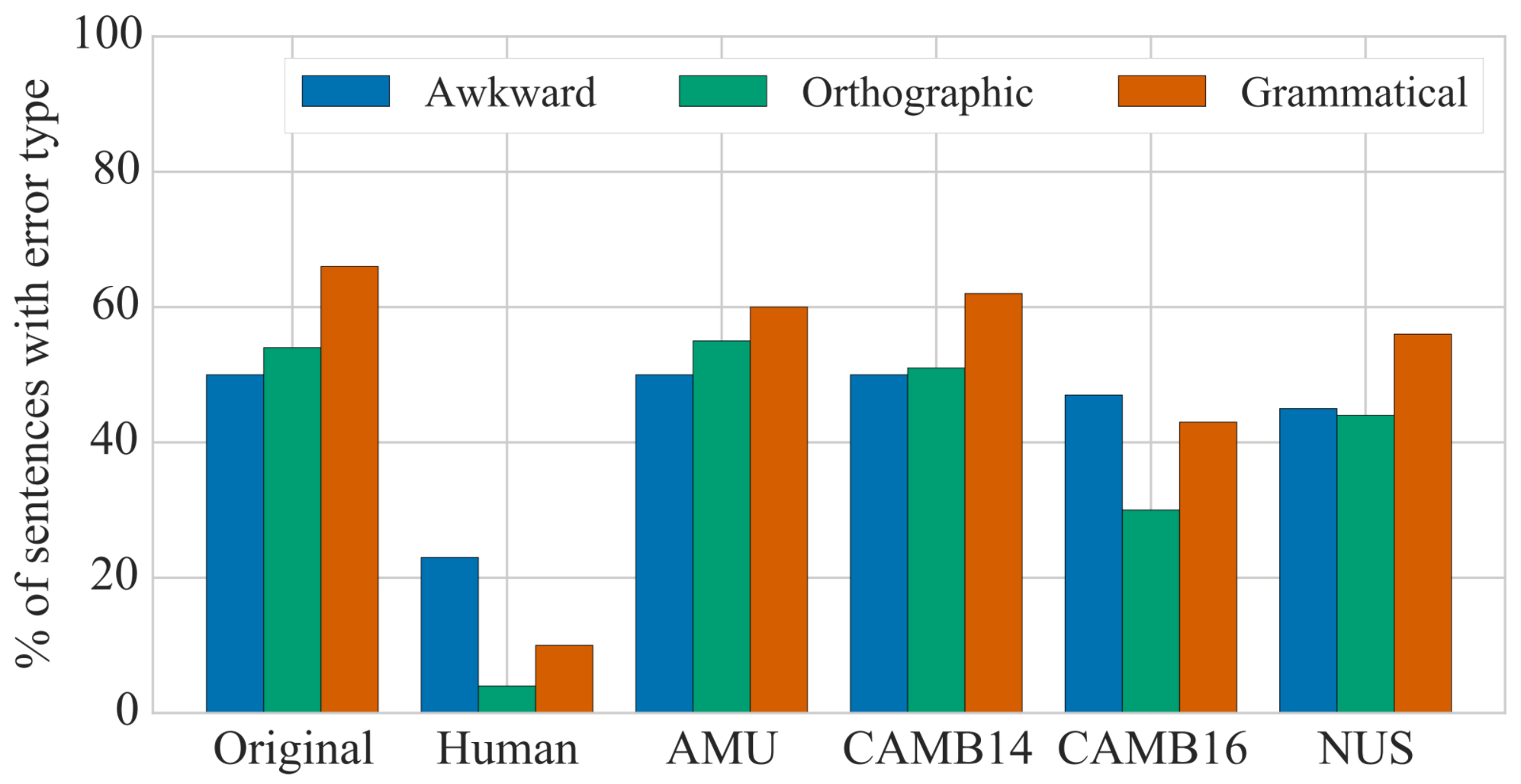
Surprisingly, we found that the system that was the best at making minimal edits, AMU, did not actually fare as highly on fluency edits. Also interesting is that the two systems that were driven by deep learning (NUS and CAMB16) actually produced more fluent-sounding sentences—but at the expense of maintaining the meaning of the original sentence. In the sample of 100 sentences, the most fluent system actually changed the meaning of 15% of the sentences. Here are some examples of how humans and the four existing academic systems corrected sentences:
| Original | First, advertissment make me to buy some thing unplanly. |
| Human | First, an advertisement made me buy something unplanned. |
| AMU | First, advertissment makes me to buy some thing unplanly. |
| CAMB14 | First, advertisement makes me to buy some things unplanly. |
| CAMB16 | First, please let me buy something bad. |
| NUS | First, advertissment make me to buy some thing unplanly. |
| Original | For example, in 2 0 0 6 world cup form Germany , as many conch wanna term work. |
| Human | For example, in the 2006 World Cup in Germany, many coaches wanted teamwork. |
| AMU | For example, in the 2 0 0 6 world cup from Germany , as many conch wanna term work. |
| CAMB14 | For example, in 2006 the world cup from Germany , as many conch wanna term work. |
| CAMB16 | For example, in 2006 the world cup from Germany , as many conch , ’ work. |
| NUS | For example, in 2 0 0 6 World Cup from Germany , as many conch wanna term work. |
Progress in the field has come a long way, but we can continue to do better. With this analysis, we hope to create a new benchmark for evaluating grammatical error correction algorithms and to continue to improve models that can detect and correct unnatural or awkward wording.
We will be presenting our paper at the 15th Conference of the European Chapter of the Association for Computational Linguistics on April 5. The full text of the paper can be found here.






