

With Grammarly Business, we help our users communicate better and stay productive. The snippets feature is designed for exactly this: It lets you quickly choose a word or phrase from a library of saved text to insert into your chat window or email. For customer-facing teams who frequently want to reuse short pieces of text, snippets save time on repetitive typing and protect against typos and mistakes when communicating with customers.
To start using and getting value from snippets, users need to have a few pieces of commonly used text already saved to their snippet library as customized suggested snippets. This is a cold-start problem, and it could mean that users don’t end up seeing the feature even though they would find it helpful. In this article, we’ll explain how we developed a solution that enabled us to learn when a sentence was one that a user typed frequently—without ever storing any of the user’s text.
How to solve a cold-start problem
There are a few different ways we could solve our cold-start problem for snippets:
- Prepopulate the snippets library with generic snippets (like greetings). This approach helps, but only somewhat. There aren’t many snippets that are both universal and high-value. Generic greetings, for instance, can sound “canned” and are already short to type.
- Create industry- or business-function-specific snippet collections. This might help us solve the cold-start problem, but it requires a lot of research to understand which snippets would work in each industry. It doesn’t scale well either—to add another industry or business function, we would need to do more manual work.
- Ask Grammarly Business account owners or contributors to create snippets for their department. This is asking a lot of our users. It requires significant effort to set up a snippet library from scratch, and it’s unlikely that one single person has the expertise to do so.
None of these solutions was a great fit. We wanted something scalable that we could implement fairly quickly so our business users could easily discover this feature.
The solution we came up with was simple: Recommend new snippets to users based on their writing habits. When the user types text that they’ve frequently typed in the past, we would suggest that they create a snippet with one click. This lets us solve the cold-start problem without having to fill the library in advance, and it scales.
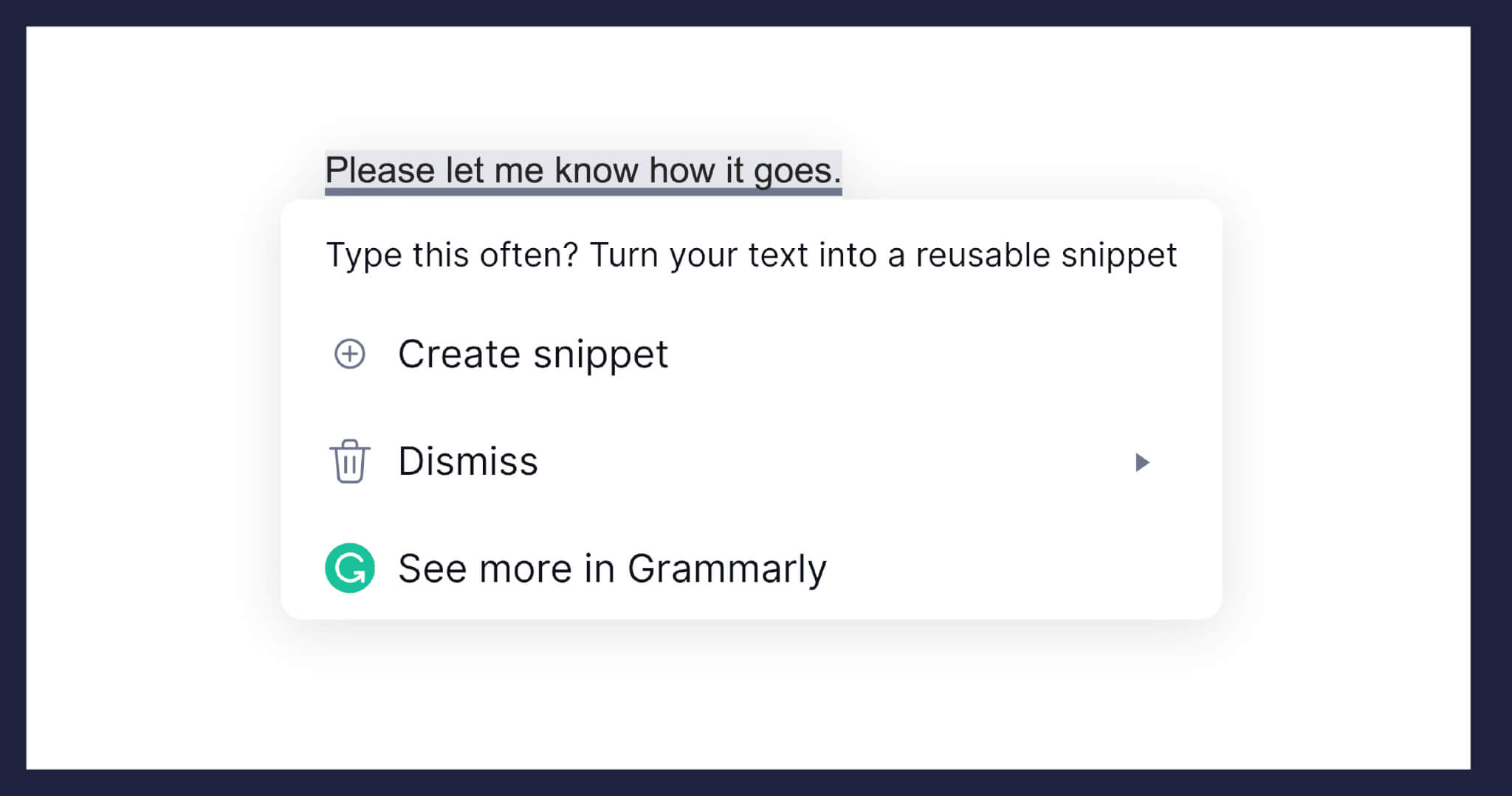
However, this solution presented an entirely new challenge. When Grammarly is activated and checks our users’ writing to offer suggestions, we process their data. We don’t store user data in association with their account, though, unless text is saved in the Grammarly Editor to allow for user access. Privacy is central to how we design our service offerings. So we needed to find a way to detect users’ frequently used sentences in order to deliver custom snippet suggestions without storing text.
Implementation
To detect users’ frequently used sentences, we can’t just look for unique text, since users often write the same things slightly differently. For instance, consider the two sentences “Please let me know how it goes” and “Let me know how it went.” If the user types “Let me know how it goes” next time, we might want to suggest creating a snippet, because they’ve typed two very similar sentences in the past.
How do we accomplish this without storing user text data associated with their user ID? There is a family of hashing algorithms called locality-sensitive hashing that can help. Regular hashing algorithms need to have two properties:
1 The hash function should return the same hash value for the same objects, so it shouldn’t change over time or because of other factors.
2 It shouldn’t return the same value for all objects—otherwise, it would be a terrible hash function!
Locality-sensitive hashing or LSH defines a third property: Similar objects should have similar hashes. For example, consider the three sentences “Let me know how it went,” “Please let me know how it goes,” and “Hi, my name is Bob.” With locality-sensitive hashing, the first two sentences would have “close” hashes, while the third would be further away. Similarity metrics are usually defined as some kind of distance—cosine, Euclidean, Hamming, or other.
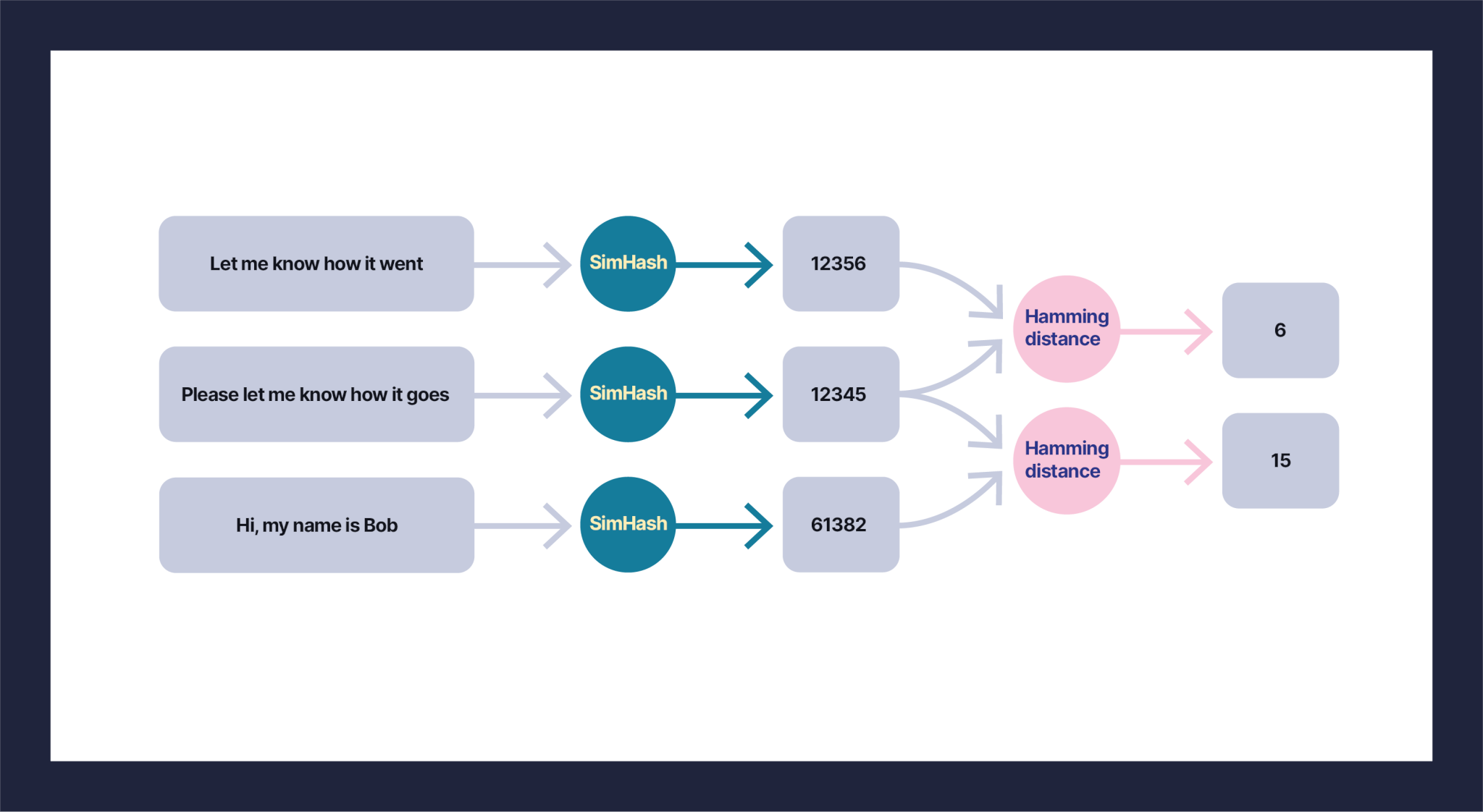
As we can see in the above diagram, the first two sentences are more similar than the second and the third. This is an example of the LSH algorithm at a very high level. There are several implementations of LSH for text data, like MinHash and SimHash. We picked SimHash as it performs faster than MinHash, and this is important because as a writing assistant, we need to provide suggestions immediately without disrupting the flow of writing. We used the Hamming distance as a similarity metric.
Thus, we have an answer to our question of how to recognize similar bits of user texts without storing that text on our servers in association with user accounts. We can store the hashed version instead of the raw text!
Architecture
Many of Grammarly’s features are spread across multiple services with one common endpoint for all requests. This endpoint is responsible for taking text and distributing it to multiple backends for processing. We added to this process by having the endpoint also compute SimHash for all sentences. This gives us the following tuple:
(userId, [sentence1, sentence2, sentence3]) → (userId, [hash1, hash2, hash3])
The hashed text is sent through Kafka to our long-term storage, where we store weekly events data for batch processing. We created a Spark job for our use case that runs daily and finds frequently used sentence hashes. The job takes all the user’s hashes based on the sentences we checked during the past week and compares them with each other by Hamming distance. We define two sentence hashes as “similar” if their Hamming distance is less than a predefined threshold. This lets us find the top n sentence hashes that had more than m similar hashes during the week. After we find the candidates, we store the results in Redis as a hash in the same format.
Key: userId, Value: [hash1, hash2, hash3]
Redis provides pretty fast access because all data is stored in memory. Every time the system checks user text and computes hashes, we can query Redis for the top n hashed user sentences. Then it checks if the user’s text contains any candidates for snippets, and if there are any, we can recommend that the user add it as a snippet. Now, if the user types “Let me know how it goes” and they have previously typed “Please let me know how it goes” and “Let me know how it went,” we could recommend that they create a snippet for the “Let me know how it goes” text. And we’ve done this without ever storing what they typed because we only stored the hashes of those sentences.
Results
When evaluating this approach, we realized we needed to develop a workaround for limitations regarding long texts. If you edit the same long document multiple times over the course of a week, this algorithm will detect many snippet candidates because the same text has been processed several times. Since the snippets feature is a productivity tool designed for customer-facing teams who usually work with short-form documents, we decided to narrow down the list of apps and exclude tools like Pages and Google Docs.
As with any new feature rollout at Grammarly, we performed an A/B test to verify that our initial hypothesis was correct. We wanted to increase the adoption of the snippets feature by suggesting users create new snippets based on their day-to-day writing habits. We measured how many users created and used snippets in each group. We ran the experiment for one month, and the results were pretty impressive: As we expected, we saw increased snippet creation compared to the users who never saw the recommendations.
This feature is an excellent example of how we can deliver significant value to our users while maintaining the highest privacy standards, so our users can trust Grammarly for all their writing—whether it’s personal or business.
Interested in solving problems like these? Grammarly is hiring. And we’d like to thank the fantastic team that worked on this project: Elise Fung, Nastya Zlenko, Nikolai Oudalov, Kirill Golodnov, and Nikita Volobuev. Thank you for your collaboration and contribution!






