

This article was co-written by software engineers Ankit Ahuja and Taras Polovyi.
Many teams focus on shipping and iterating quickly to deliver the best user experience. However, the process often overlooks performance, which can cause the user experience to gradually degrade over time. Grammarly’s Browser Extensions team wasn’t an exception. In this post, we’ll explain our journey as we realized a performance problem existed, identified its root causes, fixed the worst bottlenecks, and, finally, ensured that we won’t face issues like this in the future.
Over the years, users have mentioned to us that using our product slowed down their browsers. The input latency these users were noticing wasn’t frequent in most use cases. Still, it increased when users were working with longer documents that included many more suggestions—a common situation among our power users.
The regression was most noticeable through increased typing lag. This realization was our wake-up call: We had to prioritize improving the performance of our extension.
How we measured input latency (or, know your enemy)
At first, we only had anecdotal evidence of users experiencing significant input lag, and the users who tended to report this were working with slower CPUs or long documents using the Grammarly browser extension. Here, we define text input lag as the delay between the user pressing a key and the corresponding character appearing on the screen. We were particularly interested in understanding and reducing the impact of the Grammarly browser extension on this lag.

Illustration of text input lag on a long document with several Grammarly suggestions
But anecdata wasn’t enough: To efficiently measure our changes’ effectiveness and plan our future work, we had to establish a baseline that could allow us to compare changes objectively. We decided to focus on keyboard input latency overhead introduced by the Grammarly browser extension as our main metric.
In the context of our work, we measured the input lag in the text fields where Grammarly was actively assisting the user. In order to perform its task, the extension should keep track of all text changes and update the suggestions in real time. However, this introduces the risk of executing many computationally expensive operations in a way that would degrade the user’s experience.
Lab-based benchmarking
Our eventual solution had to allow us to continuously measure performance, monitor the health of the production environment, and highlight potentially risky changes before they were merged into the main branch.
Since the subject of the measurement is not a particular web application but a browser extension, we couldn’t just capture the duration of a keypress handler execution. This would also include the overhead introduced by the host page scripts, which would make it less precise.
To resolve this dilemma, we set up an isolated environment based on Playwright and Chrome performance profiling that could determine the “cost” of Grammarly by running a set of common user interactions on the same website with and without the Grammarly browser extension installed. After typing each new character, the test captures the duration of the main thread being blocked using window.requestAnimationFrame().
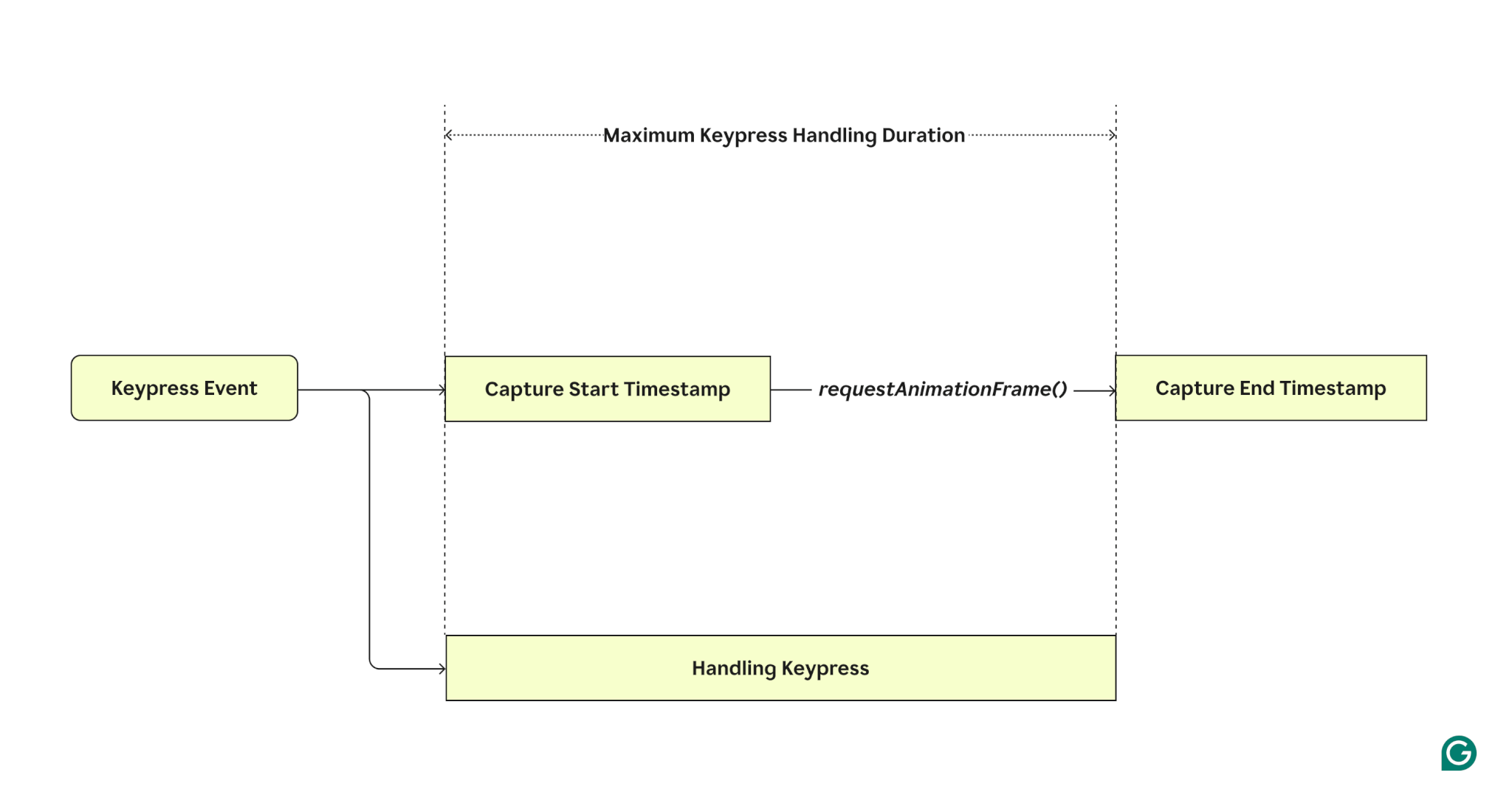
Once we executed every scenario enough times to receive high-confidence data, we subtracted the mean latency of runs without the extension from the mean latency of runs with the extension installed. This gives us a number that represents the overhead introduced by the extension. The results were then visualized in Grafana and used for monitoring the performance of new features.
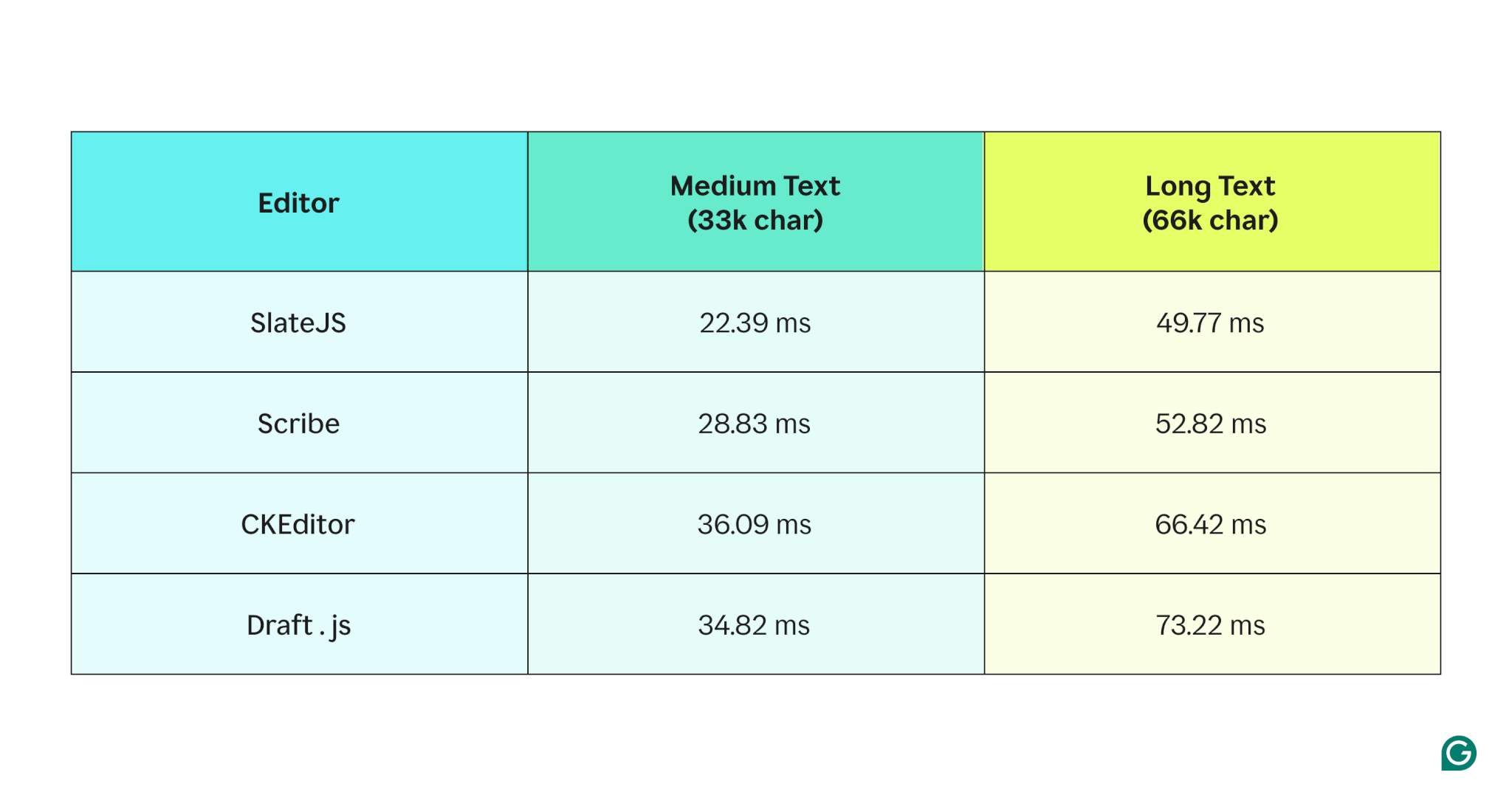
Initial local benchmarking results indicating text input lag added by Grammarly
This solution worked well for getting us a specific number, but it was isolated from the real world. Even though we saw improvements in the lab environment, we couldn’t use those results to represent the impact on actual users. We had to set up performance observability for production.
Measuring input latency in the field
Just like in the performance tests, we measured the time from the event firing to the next render to measure individual keypress performance. But in this case, we were trying to get data on a production scale, and that comes with unique challenges.
If we were to capture the timing of every single keypress, we would introduce a lot of load on our data infrastructure, but we would likely not benefit from such a large volume of data. As a result, we decided it was best to sample the events so that they would still be representative while allowing us to process and store only an essential amount of data.
Session-level sampling is the simplest approach. At the beginning of each editing session, we “roll the dice” to randomly determine whether we should take the performance measurements. The probability is configurable and varies from 1% to 10% because different websites generate various amounts of traffic, which means it takes different amounts of time to achieve a high-confidence dataset.
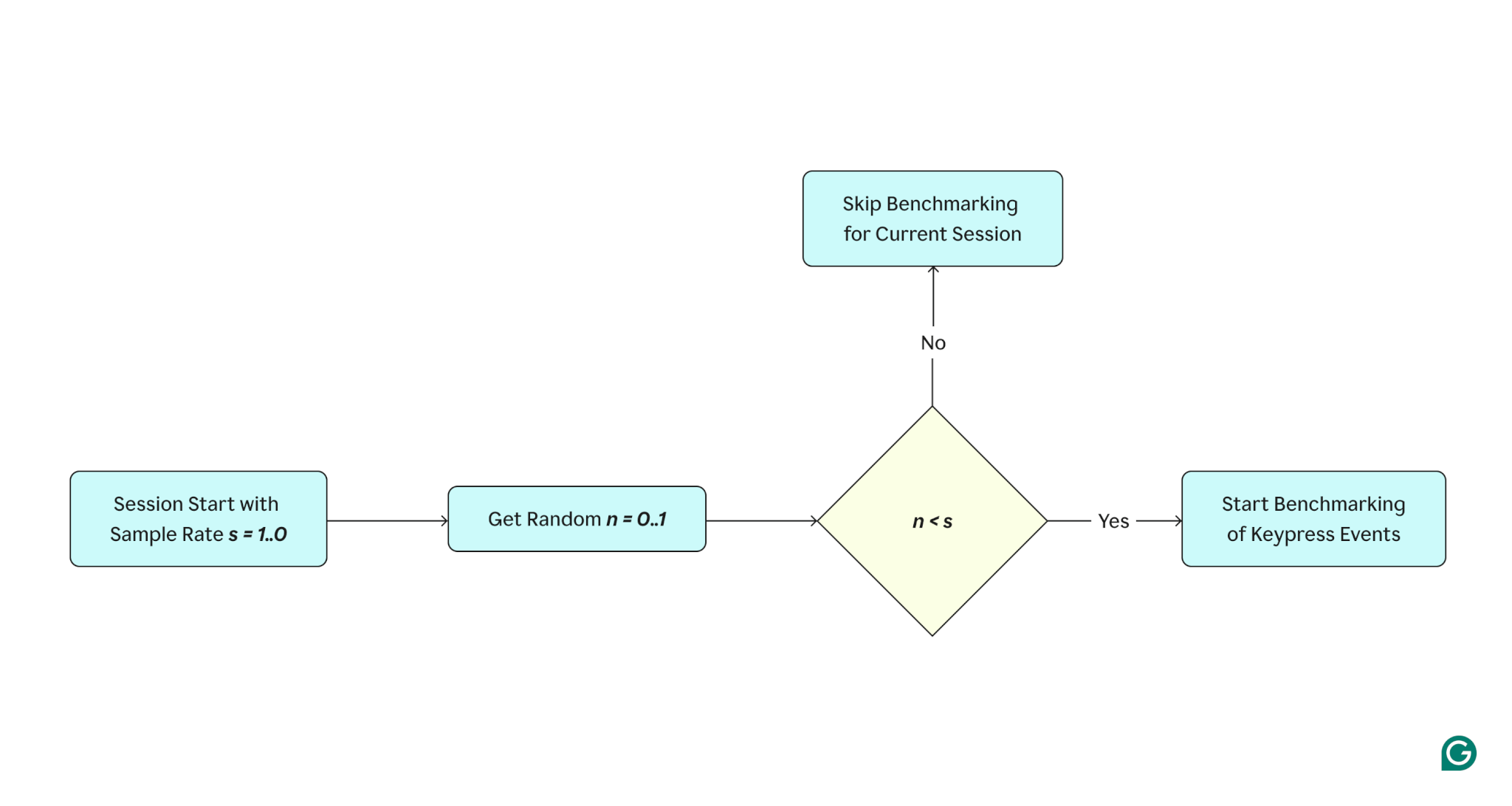
But there was another problem: Users type different amounts of text during their sessions. For example, one user could have a slow setup while writing a lot of text (a science paper, for example), while 10 users from the sample with faster systems might only write small amounts of text. In these cases, the data from a single power user might outweigh others, skew the data, and show worse benchmark results.
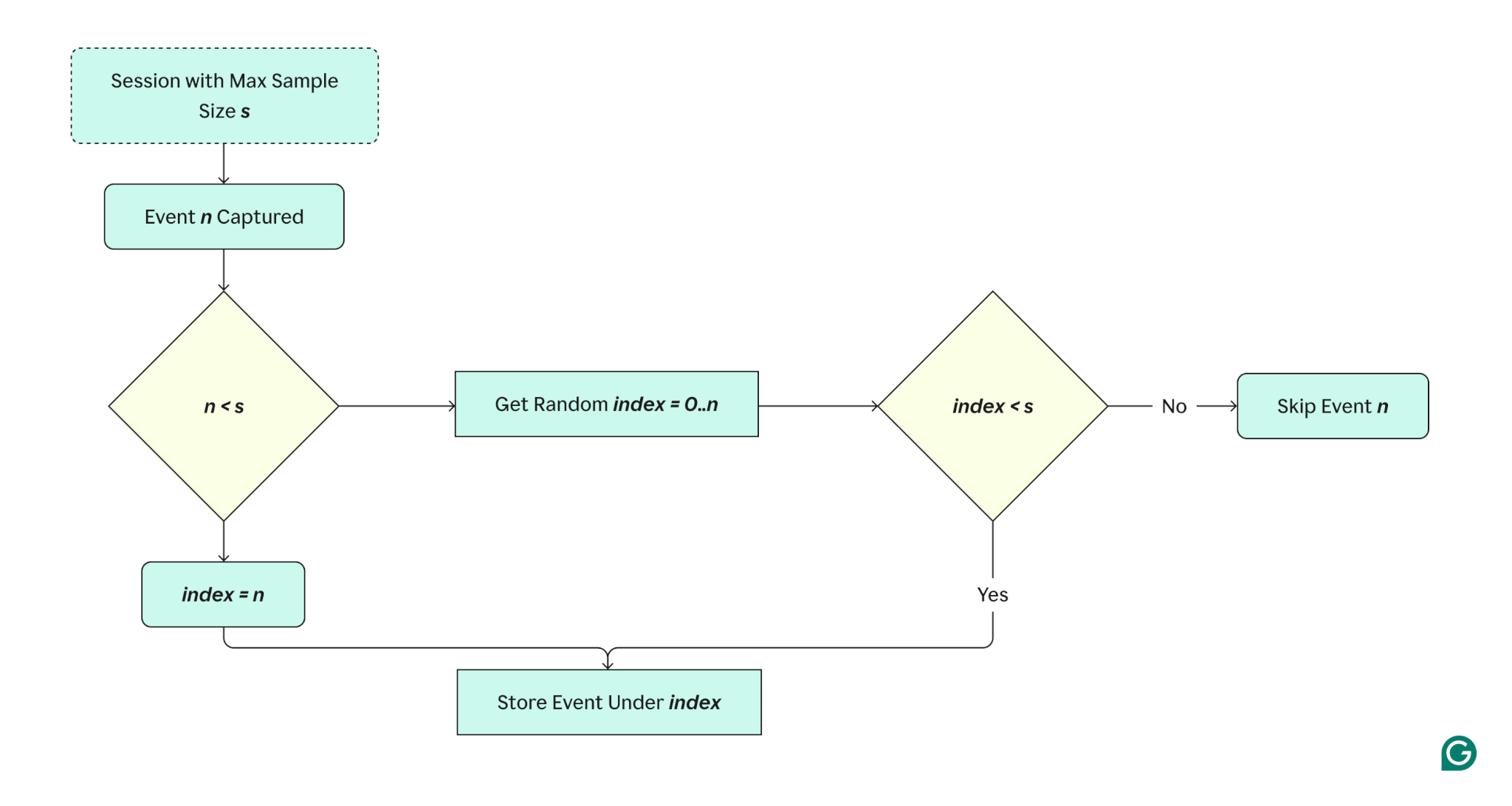
To solve this problem, we limited the number of events recorded from each session to 10. This meant we also needed to account for the fact that the conditions might vary within one session. For example, the text might grow significantly throughout an editing session, so if we just captured the first n events, the data would be biased because we wouldn’t represent the performance issues that could come during the later stages of editing.
There are quite a few ways to address this kind of problem. We chose to use Reservoir Sampling (specifically, Algorithm R). Reservoir Sampling guarantees that each event in a given stream has an equal chance to be selected without knowing in advance the overall number of events in the stream.
The combination of “lab-based” performance tests and “real-world” performance observability allows us to be more confident in the changes that we make to our codebase every day.
Analyzing areas of improvement
Our next step was to dig into the Chrome performance profile with Grammarly installed to identify areas for improvement.
We soon realized that we were running many of the most expensive computations on each keypress. Even though we identified other opportunities to reduce work on the main thread, we tagged them as lower priorities. Our initial focus was to identify work done on each keypress and how we could minimize it.
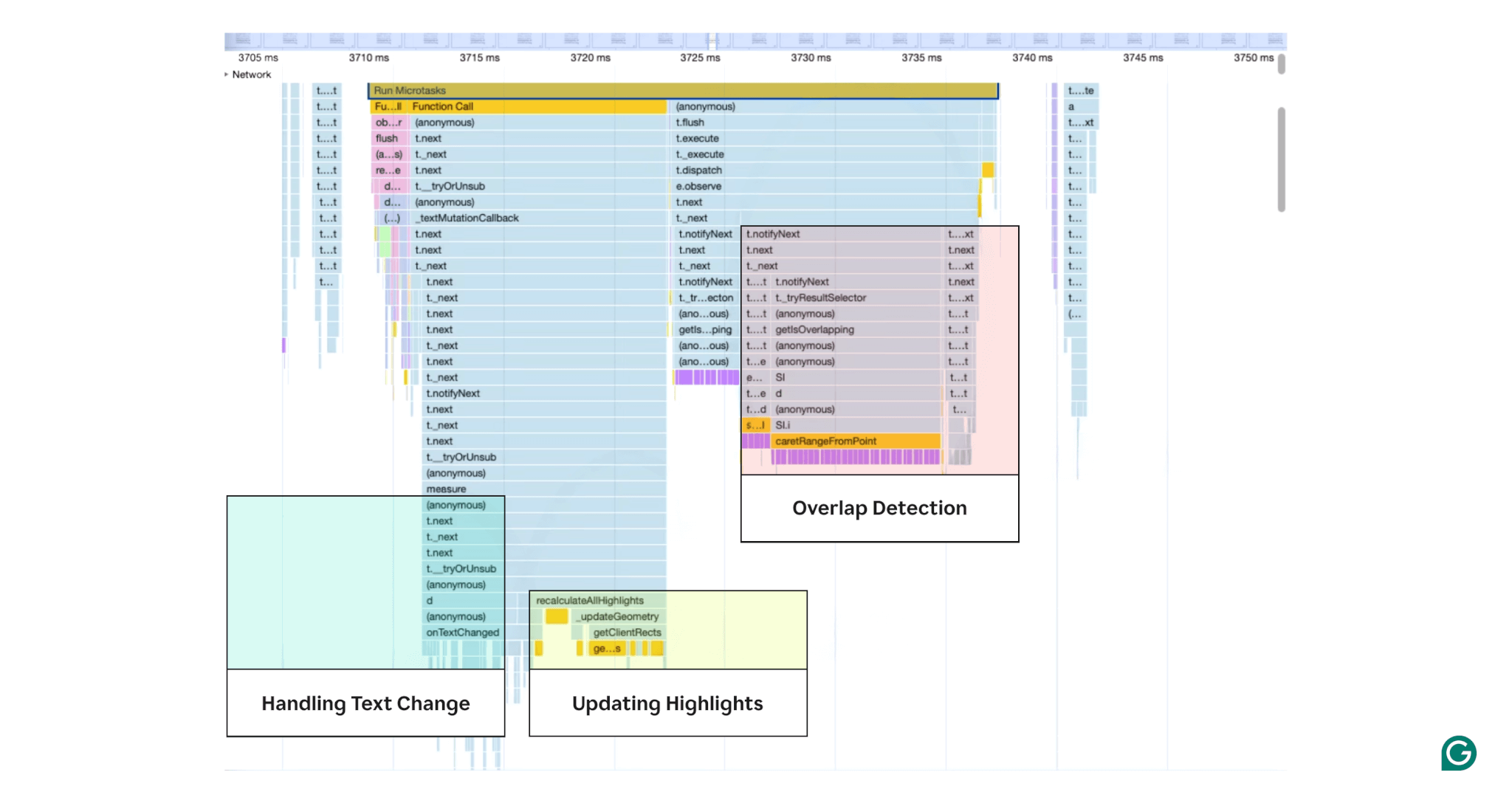
Example Chrome profile illustrating heavy areas of computation on keypress
The Chrome profile above illustrates some of the computations done on each keypress. In this analysis phase, our local benchmarking tools helped us estimate the impact of these different areas. This allowed us to create a build that removed one area of work at a time, and then to measure the resulting text input lag.
- Overlap detection with text: On each text change, we computed whether the Grammarly button overlaps with the user’s text. If yes, we collapsed the Grammarly button.
- Handling text changes: On each text change, we updated the Grammarly suggestions to eliminate redundant suggestions and updated the text coordinates for suggestions.
- Updating highlights: As the Grammarly suggestions updated, we would visually update how it displayed underlines.
With this analysis done, we were able to start implementing our solutions.
Implementation
Using our lab and field research results, we developed three solutions: a new UX for the Grammarly button, optimized underline updates, and asynchronous processing for suggestions.
Changing UX to improve performance
On each text change, we computed whether the Grammarly button overlaps with the user’s text. This was particularly expensive due to calls to the caretRangeFromPoint DOM API.
To reduce this cost, we decided to experiment with a new UX that delayed the overlap check until the user stopped typing. The visuals below show a diagram of the old UX, a diagram of the new UX, and an illustration of the new UX in action.
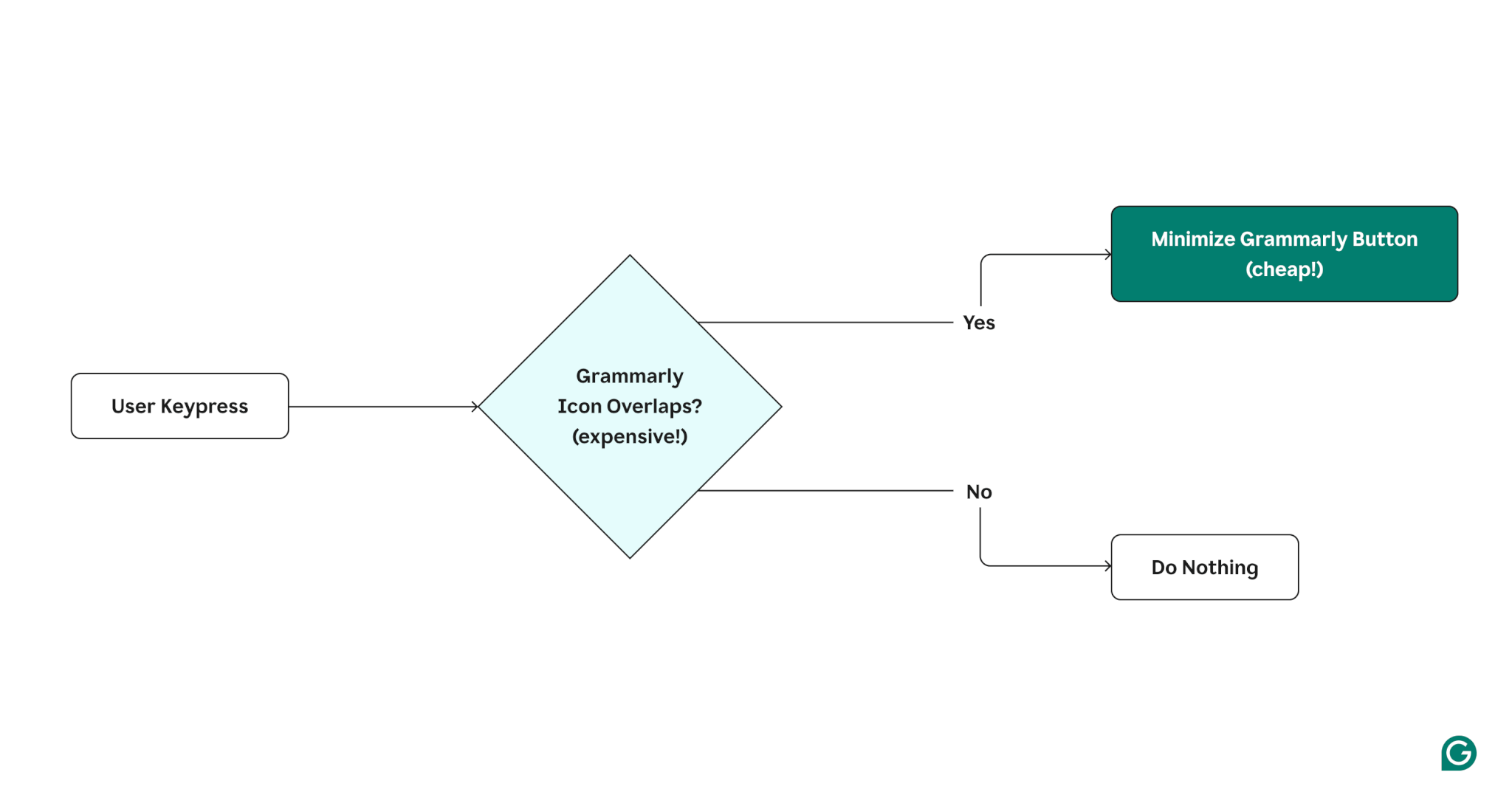
Old UX (with expensive overlap check on each keypress)
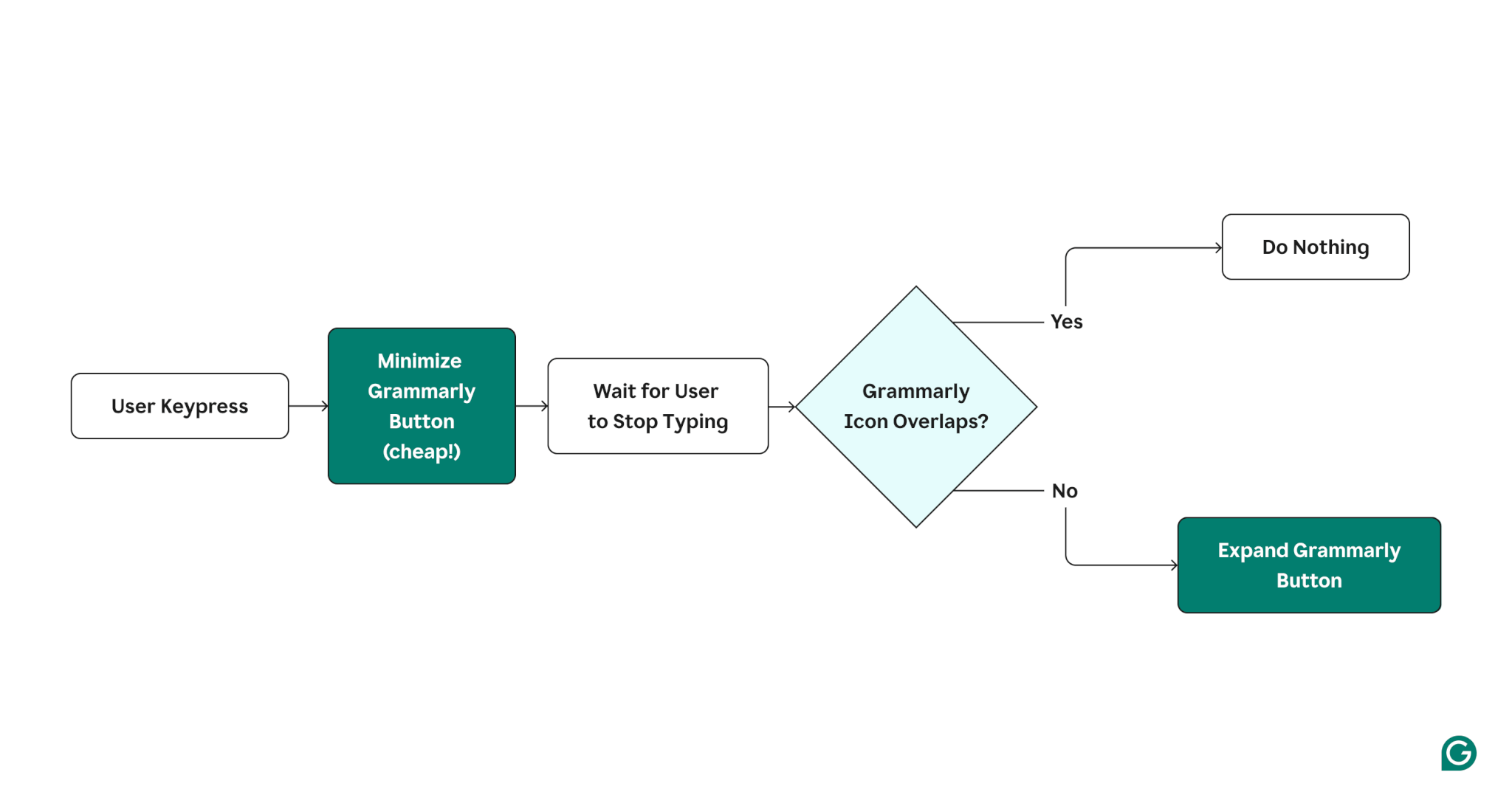
New UX (delaying the overlap check until the user stops typing)

Illustration of the new performant Grammarly minification UX
We hypothesized that users might prefer this new UX since the Grammarly button would collapse by default when they were typing, making it less distracting.
In addition to the performance improvements, we found that users preferred this experience because it reduced the number of cases where Grammarly interfered with writing. As a result, the number of users disabling the extension decreased by 9%.
Optimizing underlines updates (or, how to eat an elephant)
As we mentioned previously, updating the positions of the underlines (what we call “highlights” internally) was one of the most significant contributors to overhead on keypress events.
Generally, Grammarly doesn’t interfere with the actual HTML that represents text. To render underlines in their proper place, we have to create our own text representation, which allows us to know the position of each character in the text on the screen based on the computed styles of the editor.
The challenges start when a user decides to modify the text. Once this happens, we need to update the geometry of each affected underline to match the new positions of words on the screen. We have to use a relatively expensive DOM API to detect the position of every underline. This becomes a challenge for long documents, where the number of underlines can rise to hundreds.
Our team discussed multiple ideas for addressing this.
At first, we considered deferring the execution until the user stopped typing. We decided this wasn’t suitable because it would result in the underlines being positioned in the wrong places for a noticeable amount of time.
Next, we tried to move the process into a separate thread (i.e., WebWorker), but they do not allow access to the DOM, meaning that the most expensive part of the update would’ve stayed in the main thread.
We were left with one option: figure out a way to perform this long task in the main thread as early as possible without interfering with user input.
After some prototyping, we came up with a solution that met our requirements. We allocated a fixed timeframe for processing as many underlines as possible without introducing a noticeable lag. Once the time runs out and some underlines aren’t updated, the next chunk gets scheduled using window.requestAnimationFrame() API. The process continues until there are no items left unprocessed.
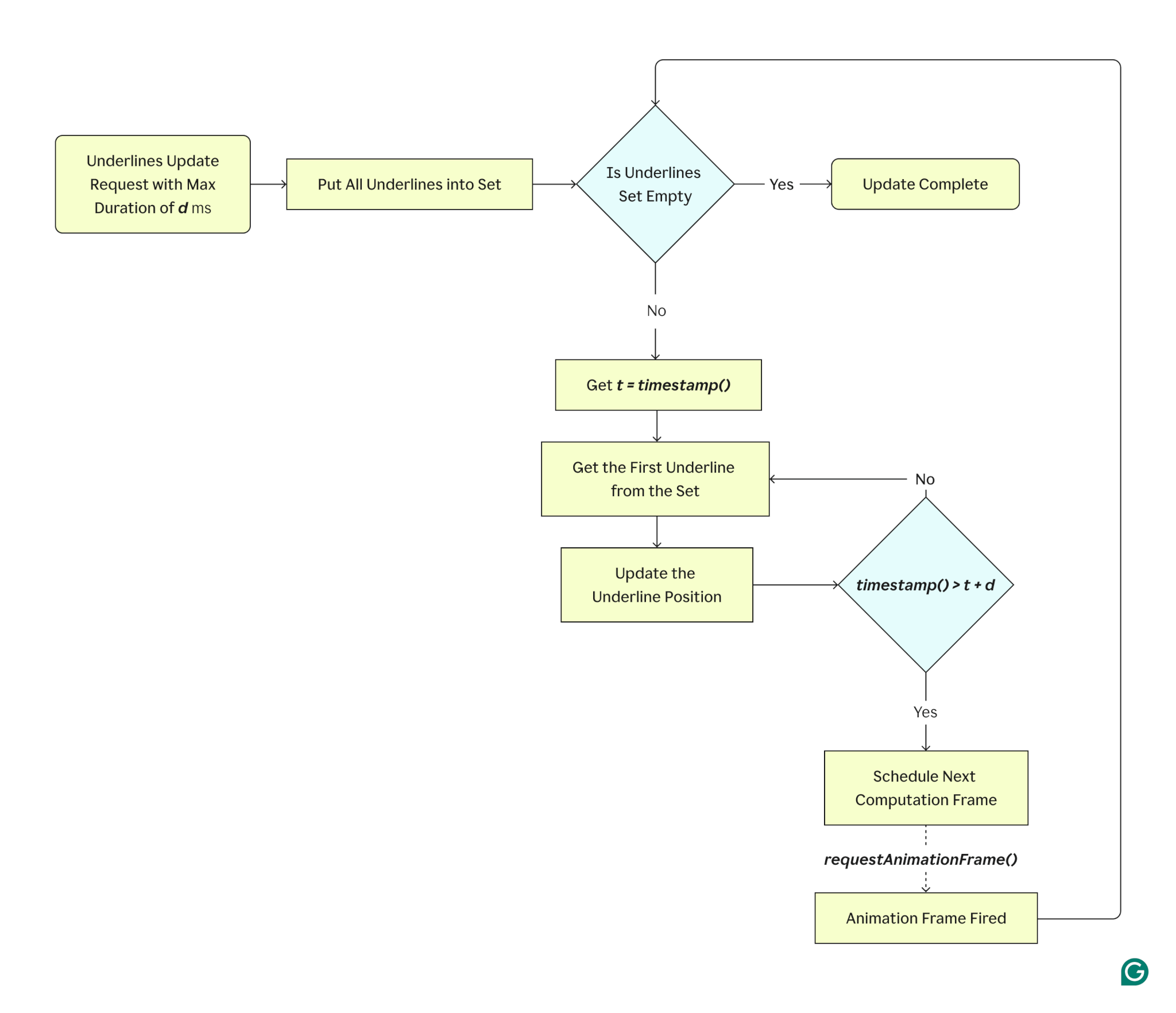
In this scenario, the user might still be typing, meaning a new geometry update might be necessary before the previous task is fully complete. To handle this, the underlines scheduled for the update are put into a Set structure, ensuring that we won’t run the process for the same underline twice.
Another benefit of this approach is that it doesn’t change the user experience in the vast majority of scenarios. Since the first computing window is synchronous, the underlines are repositioned on most setups the moment a text change is detected.
In less common cases with large documents, the complete update might take several animation frames. This does leave room for some inconsistencies, but during our testing, these inconsistencies were barely noticeable—even on extremely long documents.
This optimization helped us improve input latency by up to 50%, depending on the type of editor the Grammarly browser extension was integrated into.
Asynchronous processing of suggestions
The processing of updating suggestions on text input was the most significant contributor to input lag because it also triggered highlight and DOM updates.
Instead of updating suggestions with each text change, we wanted to wait for the user to stop typing and then update suggestions. Users don’t interact with suggestions until they’re done typing (except in cases like autocorrect), so we anticipated that this approach would work.
We needed to redesign suggestion updates to be asynchronous. We developed an incremental solution that allowed us to apply asynchronous updates when the user has stopped typing while still supporting other synchronous processes.
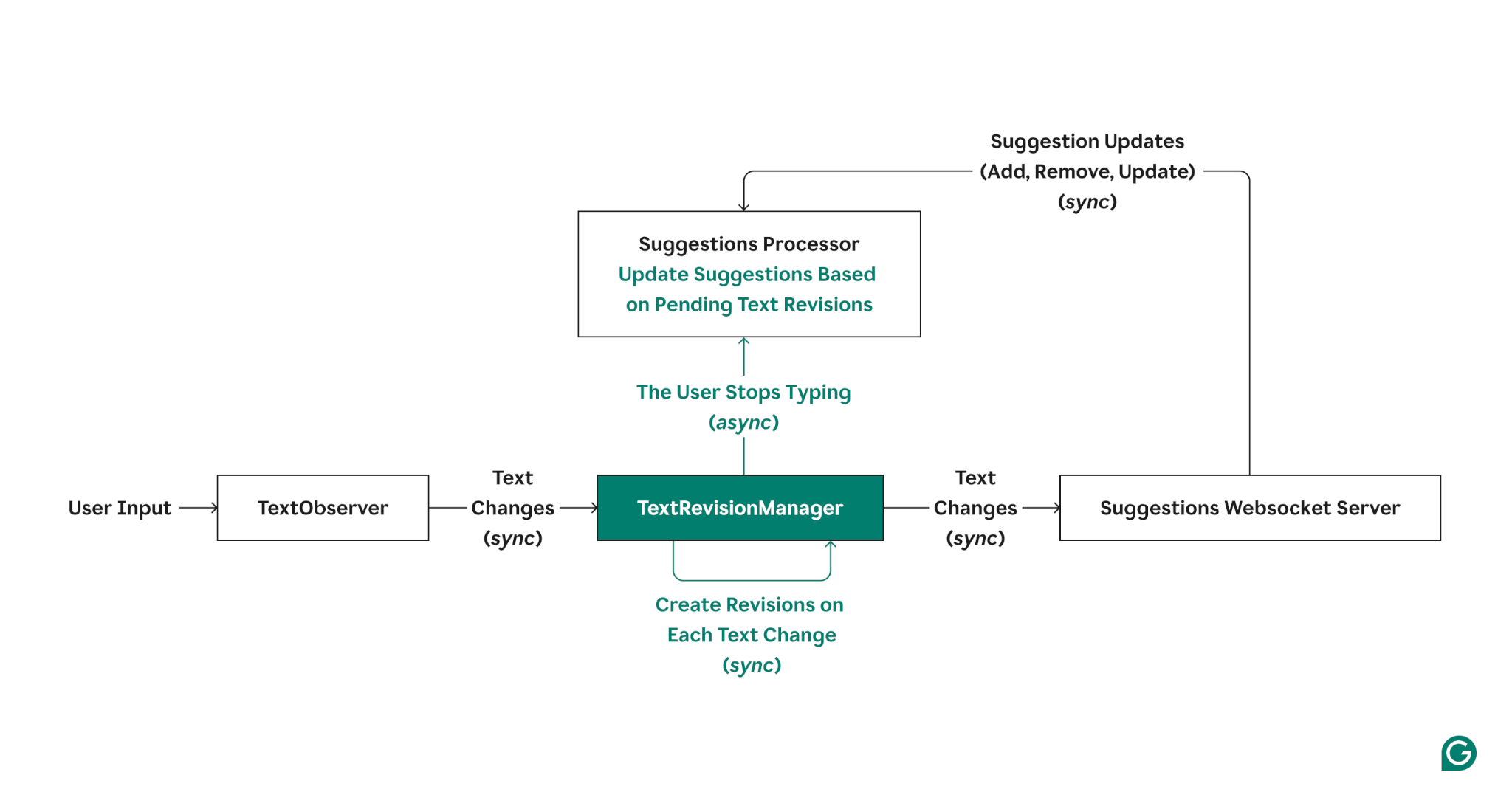
Simplified architecture diagram illustrating new abstractions and concepts added to suggestion updates (highlighted in green)
As a result of this redesigned architecture, we were able to change the way suggestions worked in a few key ways, including:
- The extension now buffers text revisions and visually updates the highlights by one character when the user is typing.
- Once the user stops typing, the extension processes any pending text revisions.
- The extension processes pending text revisions when any synchronous APIs are called (until all APIs can be made asynchronous).
Results and lessons learned
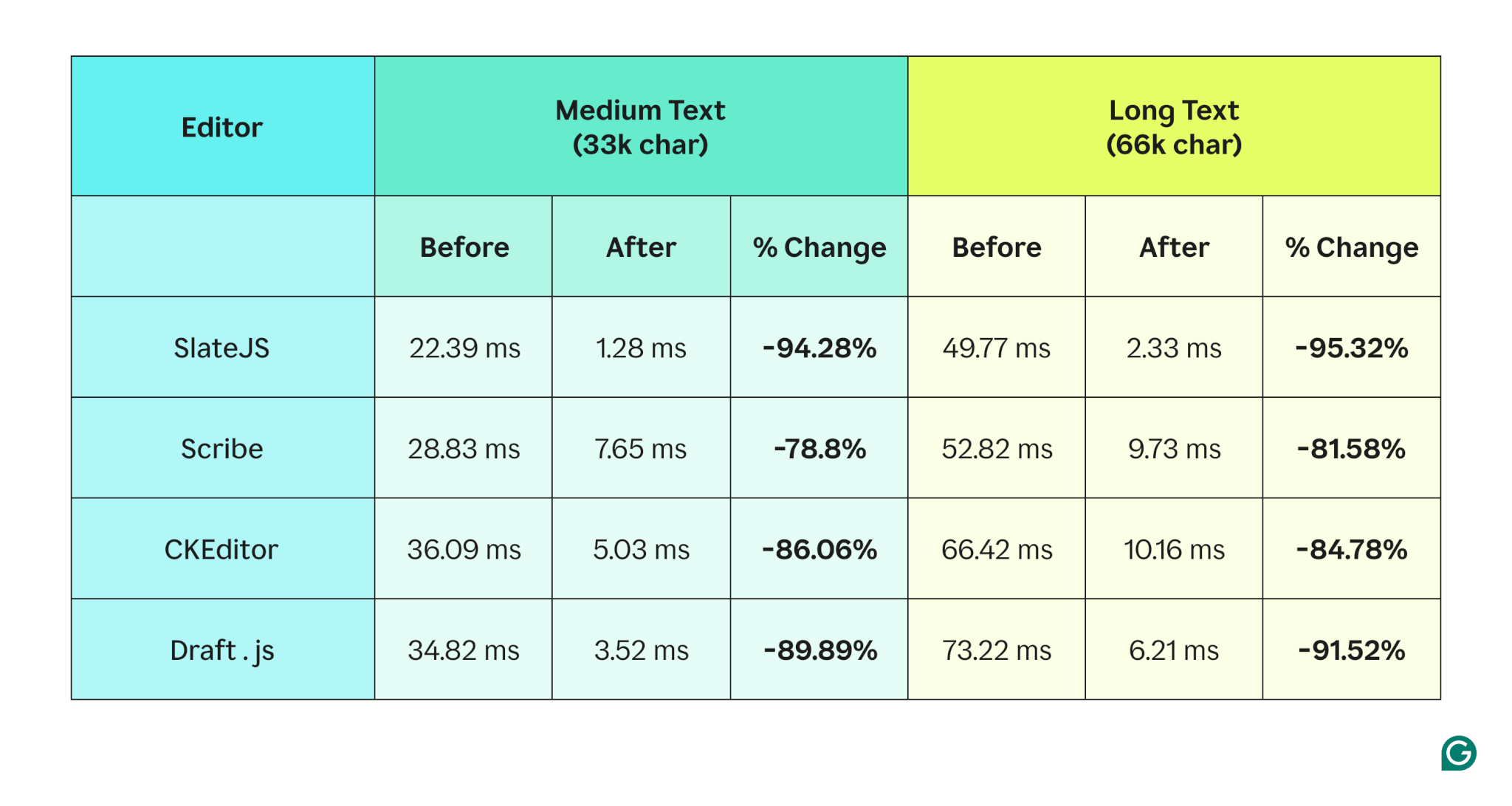
We achieved significant improvements, both in terms of objective performance and subjective user experience.
- Overall, this work reduced text input lag by ~91%.
- Optimizing underlines improved input latency by up to 50%, depending on the type of editor the Grammarly browser extension was integrated into.
- Users preferred the new UX we originally built for performance reasons, so this work also decreased the number of users disabling the extension by 9%.
- We received positive feedback from Grammarly users who were previously facing input lag issues.
- We set up a robust infrastructure to track Grammarly browser extension performance over the long term, both in the lab and in the field.
Now, we’re able to prevent regressions as we ship new user experiences.
We also learned some important lessons along the way, including:
- It’s more effective to identify quick wins when tackling hard problems. Improving how the Grammarly button is minimized gave us an early win and a platform to work on the more complex problems.
- Exploring alternative user experiences allowed us to delay the execution of code when users weren’t interacting with the webpage.
- When possible, design your web application so it can run things asynchronously and without relying on synchronous events. This allowed us to break up long tasks and avoid blocking the main thread.
- Using both lab-based and field-based performance metrics is imperative. Lab-based metrics helped us track progress as we worked on improvements and prevented regressions as changes got merged over time. Field-based metrics helped us reflect the users’ real experiences based on their different environments and helped us prioritize performance work.
Performance is often deprioritized when new features on the roadmap are being built—either because we assume users won’t notice relatively slight improvements or because we assume only the rare power user hits performance limits. But, as we discovered, performance is a feature, and significant enough improvements benefit everyone.
What’s next?
We are still working on improving the performance of the Grammarly browser extension, including memory and CPU usage. We’re now measuring INP (Interaction to Next Paint), for example, to ensure we track input lag more holistically in the field. We are also working on breaking up the long task of updating suggestions into smaller tasks and exploring delegating work to a web worker.
Improving performance is a project that’s never done, and it’s another example of how we work to give our users the best experience we can. If that goal resonates with you, check out our open roles and consider joining Grammarly today.






